 Model · Chinese GEC
Model · Chinese GEC
Yanlan Model
Next-generation Chinese grammar correction across text, video subtitles, audio transcription, and image OCR — built for production scale.
Yanlan is a Chinese grammar-correction model trained with a multi-stage RL pipeline, built around the lived constraints of production deployment: false-positive rates that don't waste editors' time, throughput that handles a daily news pipeline, and a cost profile that runs on a single mid-range GPU. The model handles plain text but also reads video subtitles, audio transcripts, and image OCR — so the corrections happen where the content lives.
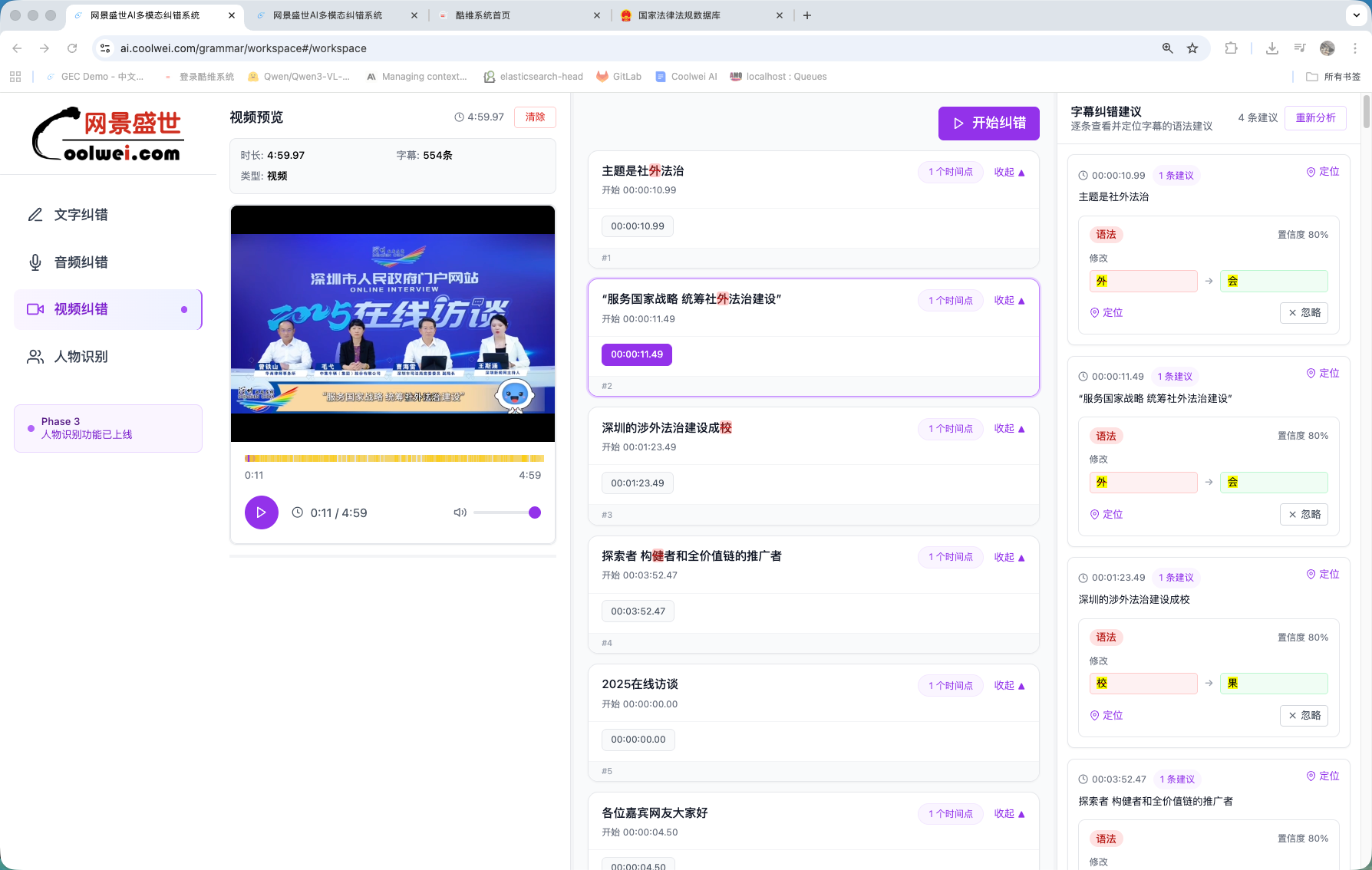
Video subtitle correction
Hook Yanlan into the subtitle pipeline and it audits every line in stride — typos, mis-recognised characters, mismatched terms — at 99%+ accuracy and roughly 1–5 seconds per minute of video. Used by editorial desks shipping multilingual subtitles on a daily cadence.
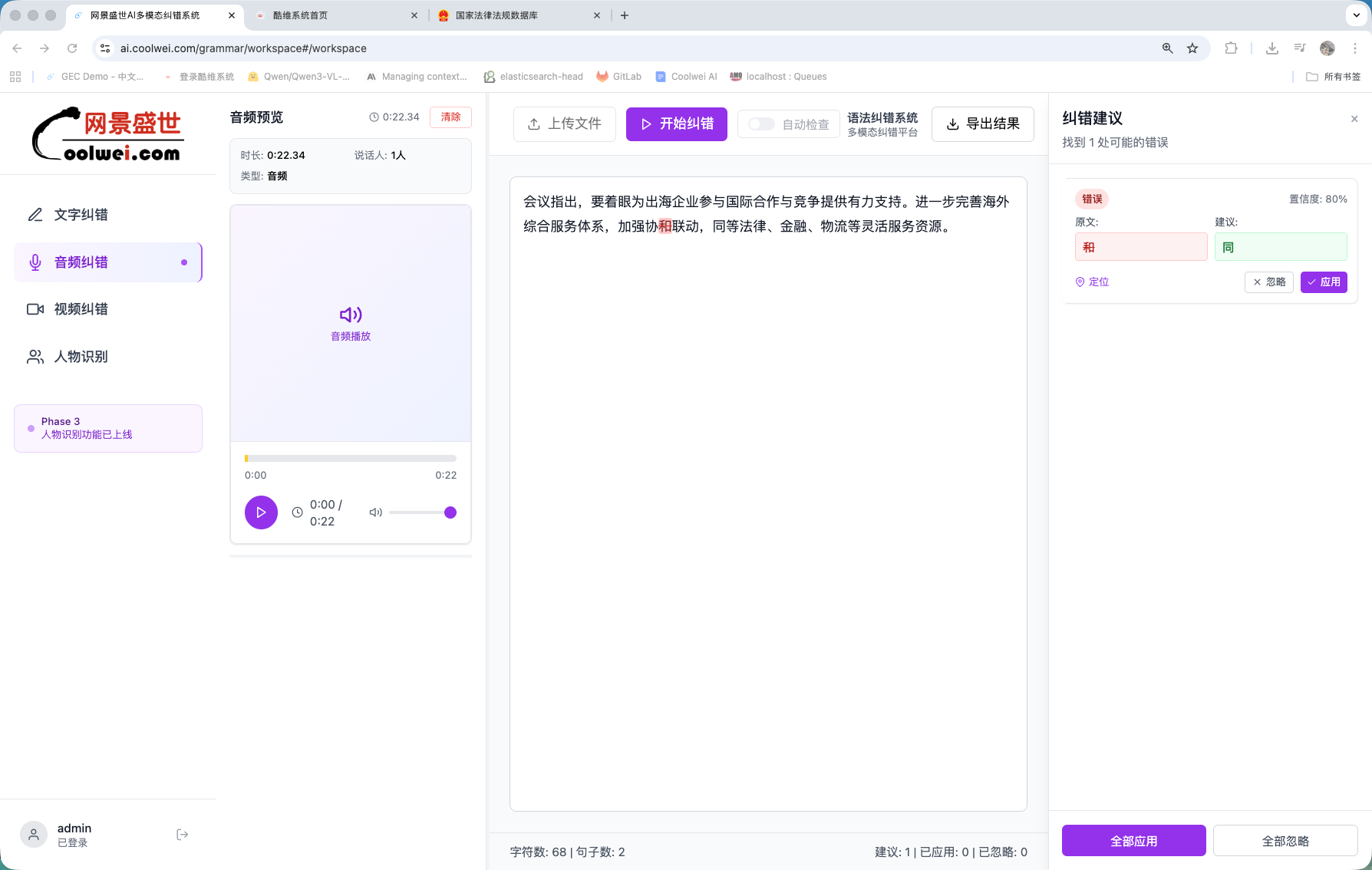
Audio transcription correction
ASR transcripts arrive noisy. Yanlan reads them with the audio context in mind, fixes mis-heard homophones, normalises proper nouns, and respects dialectal forms instead of flattening them. 96%+ accuracy across major Mandarin variants.
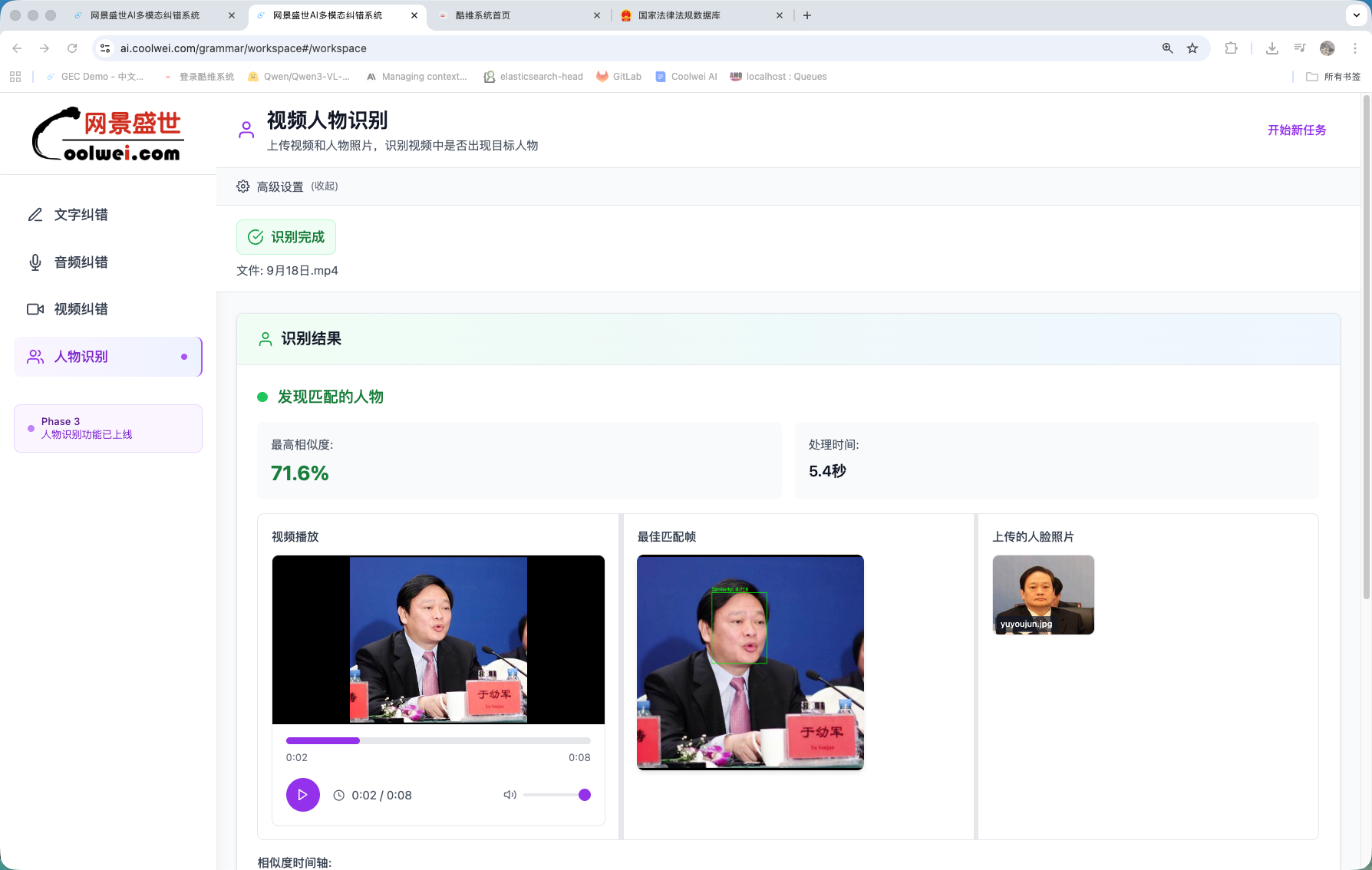
Identity check on faces
Beyond text: Yanlan ships with a face-verification head trained for compliance review on broadcast and stream content. 98%+ recognition accuracy with a 20–30× speedup over the manual review pipeline.
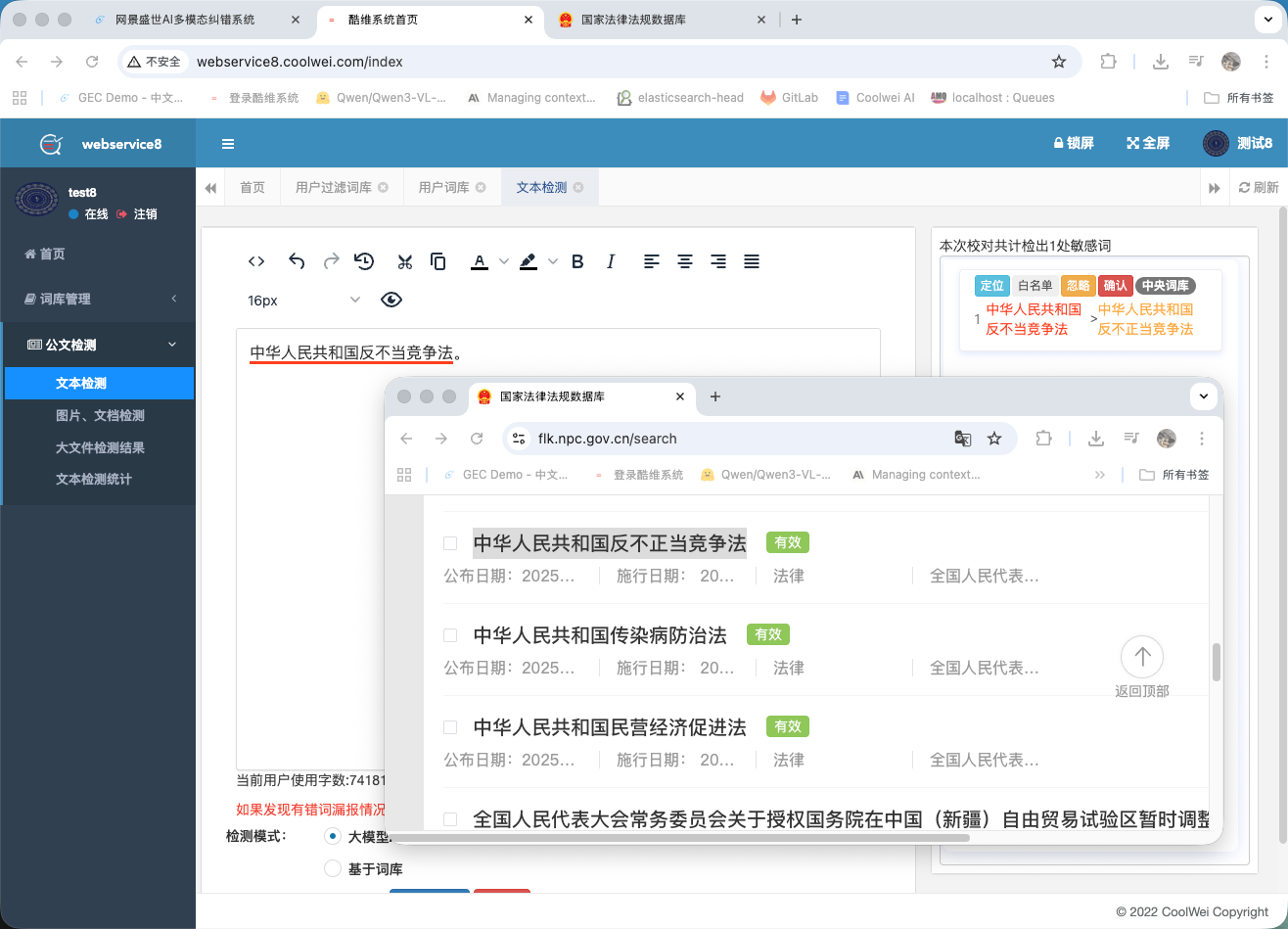
Regulatory compliance check
Anchored to a corpus of 16,740 Chinese laws and regulations with daily auto-updates, Yanlan flags content that conflicts with current rules — useful for legal review on government, media, and education output.
Performance, against the obvious baselines
Numbers below are on Yanlan's internal Chinese GEC eval set, head-to-head against the strongest commercial baselines we could reach. All three metrics matter — a model that's accurate but slow doesn't ship; a model that's fast but expensive doesn't survive contact with finance.
| Metric | Yanlan | Best baseline | Improvement |
|---|---|---|---|
| False-positive rate | 0.5% | 5% | 10× |
| Throughput (chars/sec) | 30,000 | 2,000 | 15× |
| Deployment GPU class | RTX 4090 | H100 | 10× cost |
How it works
Yanlan runs as a multimodal perception layer that normalises text, audio, image, and video subtitles into a common token stream, then routes through a classifier that selects between a central dictionary of standard Chinese, a custom dictionary tuned per deployment, and a correction model. A post-processing integration layer merges results before output.
Training is multi-stage RL on top of a Chinese-tuned base: supervised fine-tuning on human-verified corrections, then RL with editorial rewards that explicitly penalise false positives — that last step is what gets the false-positive rate down to 0.5%.
Ready to clean up your Chinese content pipeline?
Drop in a sample, see the corrections side by side, then talk pricing.
Try Yanlan →