Chess engines have outplayed world champions for years, but ask one why a move is best and you get an evaluation number. Human coaches can explain; large language models are articulate but blunder on concrete positions. Grounded Chess Reasoning studies exactly that gap: can a 4B model learn to be right like the engine and explain like a coach?
Engines play well but cannot explain
The gap is not unique to chess. Many professional fields rely on expert systems that are accurate but cannot teach (a solver — a program that produces guaranteed-correct answers): the answer is reliable, yet there is no human-readable justification behind it. Like a master craftsman whose work is flawless but who cannot say why he does what he does — an apprentice can watch for ten years and still not learn the trade. Translating that deterministic expertise into reasoning a person can read and a model can learn from is a fairly general problem.
Chess happens to be an ideal place to study it. Puzzles have a single best first move that an engine can verify instantly; at the same time, chess reasoning is unfriendly territory for large models — applying RLVR directly (reinforcement learning with verifiable rewards — scoring only whether the final answer is right) barely gets training off the ground. That combination of difficulty and verifiability makes chess a fitting testbed for “distill the expert process first, then reinforce it with correctness.”
Master Distillation: translating expert knowledge into reasoning
Master Distillation combines two kinds of systems. Stockfish (the strongest open-source chess engine, far beyond human champions) supplies deterministic ground truth — which move is best. Gemini-3-Flash verbalizes the engine’s judgment into natural-language reasoning traces. A 4B-parameter student model, C1, then learns from those traces.
Training has two stages. The first performs supervised fine-tuning (SFT — teaching the model directly from demonstration text) on the verbalized expert traces; the second applies RLVR with verifiable rewards. The order matters: skipping straight to reinforcement learning barely works — when the base model is too weak there is no signal for the reward to amplify, the so-called cold-start problem. SFT seeds the capability; RLVR then amplifies it.
The composition of the training data matters too. Tactical themes in chess puzzles are naturally imbalanced, and common motifs would drown out rare ones; the paper uses theme-balanced sampling (Algorithm 1) to keep rare themes represented in the training set.
- Compute theme frequencies: f(t) ← |{p ∈ D : t ∈ T(p)}| for all themes t
- Select rare themes: Trare ← arg minK f(t)
- Initialize selected IDs: S ← ∅
- Initialize output: Dbal ← ∅
- for each theme t ∈ Trare do
- Ct ← {p ∈ D : t ∈ T(p) ∧ id(p) ∉ S}
- Sample min(M, |Ct|) puzzles from Ct without replacement
- Dbal ← Dbal ∪ sampled puzzles
- S ← S ∪ {id(p) : p ∈ sampled puzzles}
- end for
- return Dbal
What a 4B model achieves
On the theme-balanced evaluation set, C1-4B reaches 48.1% puzzle accuracy — above most frontier models in the table, and above Gemini-3-Flash (40.8%), the very model that verbalized its training traces. The reinforcement stage adds 7.2 percentage points on top of SFT.
| Model | Beginner | Intermediate | Advanced | Expert | Theme-Split | Avg Acc | Avg Tokens |
|---|---|---|---|---|---|---|---|
| gpt-5 | 95.0 | 84.0 | 54.0 | 31.0 | 85.2 | 76.7 | 12,193 |
| gemini-3-pro | 88.0 | 86.0 | 70.0 | 44.0 | 78.2 | 75.4 | 3,182 |
| gemini-3-flash | 65.0 | 59.0 | 34.0 | 19.0 | 38.0 | 40.8 | 6,418 |
| gpt-5-chat | 52.0 | 39.0 | 27.0 | 18.0 | 41.8 | 38.3 | 925 |
| gemini-2.5-pro | 37.0 | 31.0 | 29.0 | 19.0 | 31.0 | 30.1 | 9,668 |
| claude-sonnet-4.5 | 32.0 | 29.0 | 15.0 | 11.0 | 28.6 | 25.6 | 3,227 |
| claude-sonnet-4 | 35.0 | 19.0 | 16.0 | 10.0 | 26.8 | 23.8 | 8,028 |
| claude-haiku-4.5 | 33.0 | 24.0 | 14.0 | 11.0 | 25.6 | 23.3 | 8,111 |
| gemini-2.5-flash | 9.0 | 4.0 | 6.0 | 5.0 | 8.2 | 7.2 | 9,991 |
| deepseek-chat-v3.1 | 27.0 | 21.0 | 6.0 | 16.0 | 22.0 | 20.0 | 11,249 |
| qwen3-next-80b-a3b | 24.0 | 14.0 | 14.0 | 8.0 | 17.6 | 16.4 | 13,938 |
| deepseek-r1-0528 | 11.0 | 10.0 | 14.0 | 16.0 | 16.0 | 14.6 | 14,442 |
| qwen3-max | 22.0 | 15.0 | 3.0 | 16.0 | 13.8 | 13.9 | 3,393 |
| llama-4-maverick | 12.0 | 8.0 | 5.0 | 10.0 | 8.6 | 8.7 | 1,092 |
| mistral-medium-3.1 | 9.0 | 6.0 | 7.0 | 4.0 | 8.0 | 7.3 | 2,818 |
| llama-4-scout | 0.0 | 0.0 | 0.0 | 1.0 | 0.4 | 0.3 | 806 |
| gemma-3-27b | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 705 |
| C1-SFT-4B | 51.0 | 30.0 | 30.0 | 26.0 | 46.2 | 40.9 | 188 |
| C1-SFT-8B | 57.0 | 36.0 | 27.0 | 27.0 | 46.6 | 42.2 | 189 |
| C1-4B | 65.0 | 39.0 | 39.0 | 22.0 | 53.6 | 48.1 | 178 |
Output length is just as notable: C1 averages about 178 tokens per solution (token — the unit of model output, roughly half a word to a word), about two orders of magnitude shorter than reasoning-LLM baselines, closer to how a human coach explains a move in a few sentences. The ablations (Table 2) also show that data scale and theme balance both materially affect the final capability.
| Scale | Distribution | Quality | Context | SFT |
|---|---|---|---|---|
| 8k | random | flash | full | 19.3 |
| 8k | hard | flash | full | 16.2 |
| 8k | balanced | pro | full | 22.8 |
| 8k | balanced | flash | full | 20.1 |
| 16k | balanced | flash | full | 29.7 |
| 8k | balanced | flash | Multi PVs | 17.6 |
| 8k | balanced | flash | w/o Theme | 17.3 |
| 8k | balanced | flash | w/o Feigned | 16.3 |
| 39k | balanced | flash | full | 40.9 |
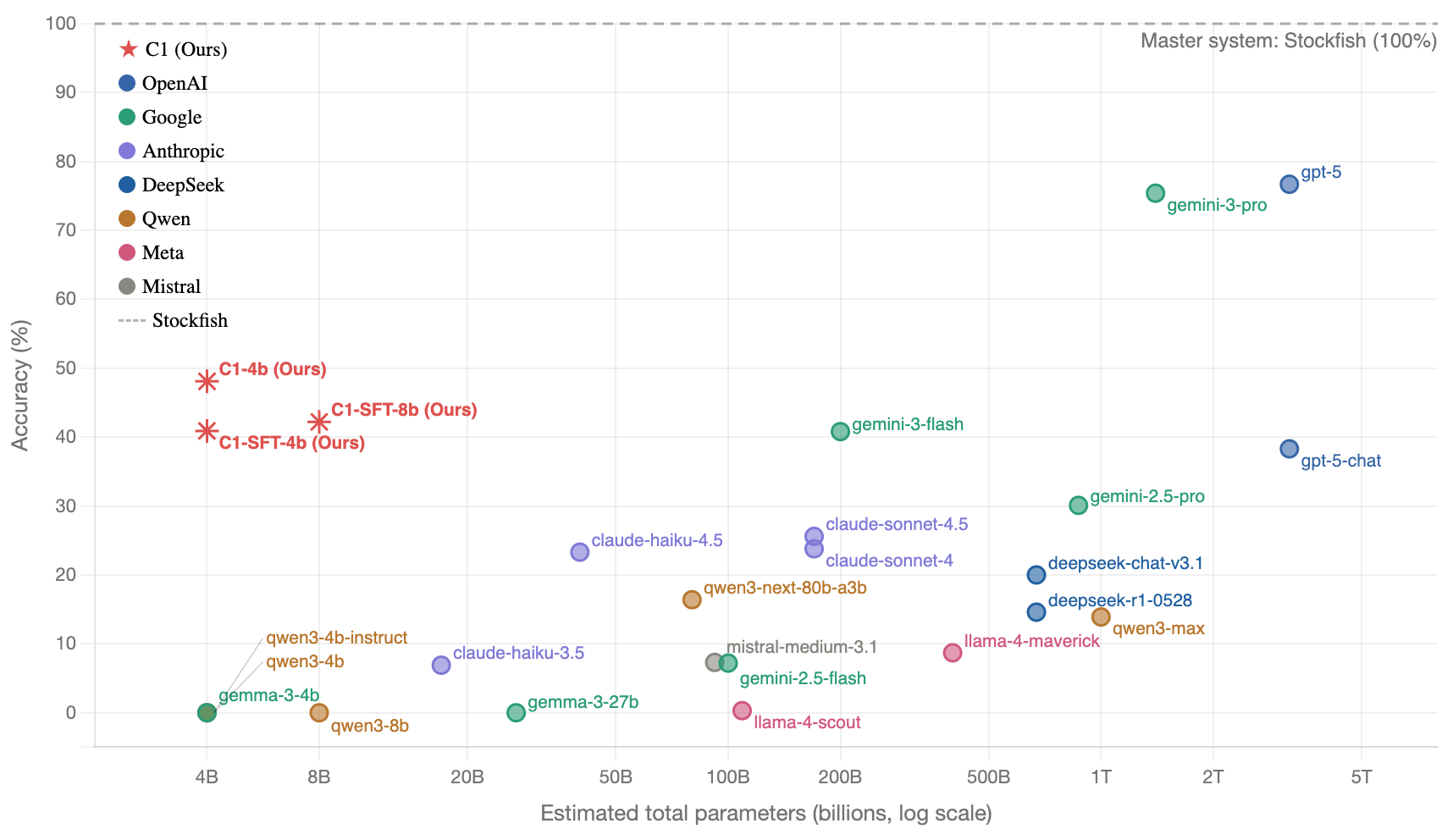
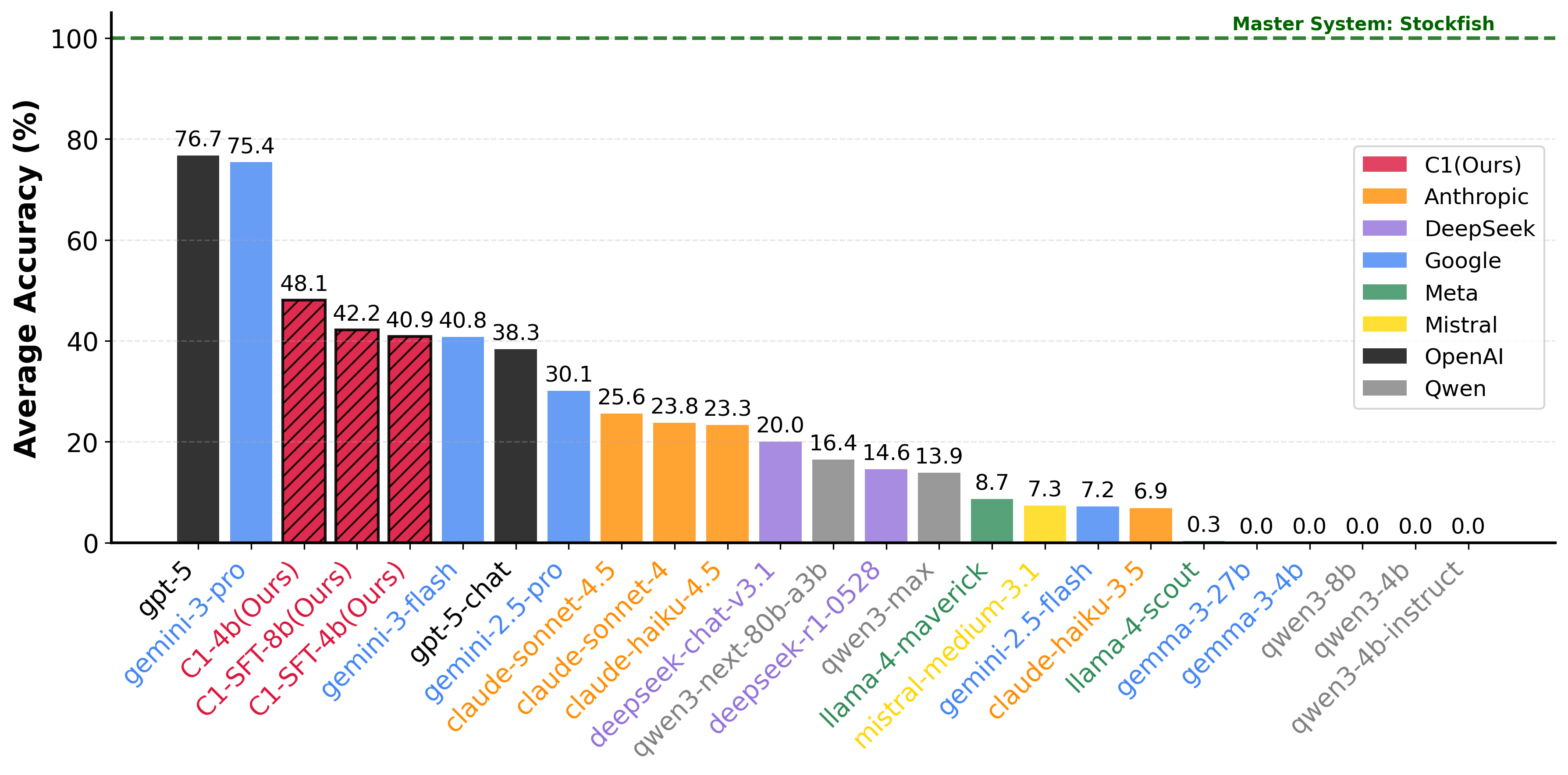
- Small model, strong reasoning.C1-4B reaches 48.1% on theme-balanced puzzles.
- Explanations are compact.It emits about 178 tokens per solution, roughly two orders of magnitude shorter than reasoning-LLM baselines.
- The student can exceed the verbalizer.Stockfish truth plus RLVR reward lets C1 outperform Gemini-3-Flash.