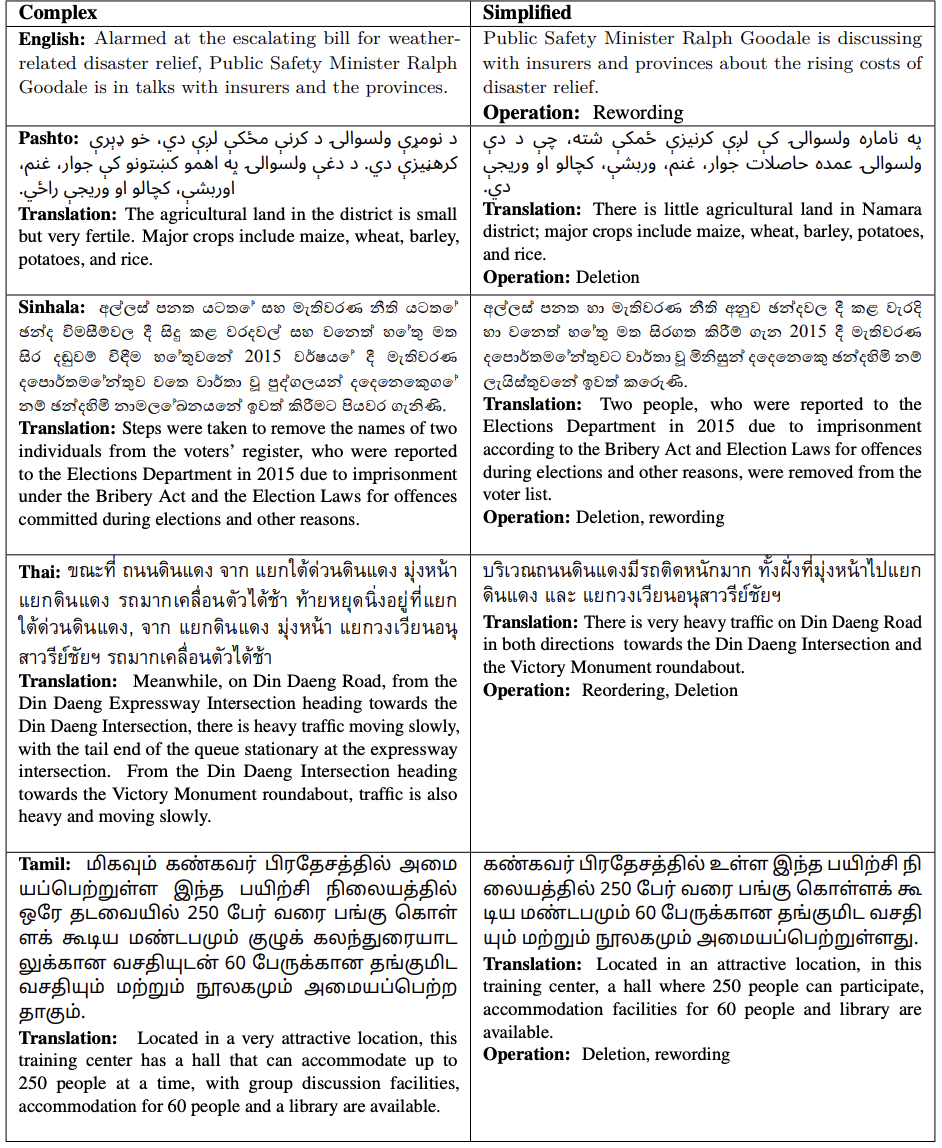
A government notice or a medicine leaflet being public does not make it readable — for second-language readers, students, and people with reading difficulties, long complex sentences are a barrier in themselves. OasisSimp builds an open evaluation benchmark for sentence simplification in five languages — English, Sinhala, Tamil, Thai, and Pashto — with all material written by native speakers.
Public is not the same as readable
The rewrite in the headline is what natural language processing calls sentence simplification: making a sentence easier to read without losing its meaning. It underpins public information, education, and accessible reading: government offices want notices everyone can follow, publishers and educators need graded reading material, and the readability of health information directly affects whether it is understood.
English simplification research has years of accumulated benchmarks to draw on. For low-resource languages (languages with scarce corpora and evaluation data) such as Sinhala, Pashto, Tamil, and Thai, there was almost no public evaluation at all — not even a yardstick to tell a good simplification system from a poor one. OasisSimp supplies that yardstick.
A benchmark written by native speakers
All source texts come from authentic settings: government documents, news, and Wikipedia. For each of the 9,519 complex sentences, native speakers wrote multiple reference simplifications under a shared guideline (multi-reference — accepting several valid ways to simplify a sentence rather than treating one answer as the only standard).
The data is split 80% test / 20% validation and fully released under CC BY 4.0, positioned as an evaluation benchmark rather than a training corpus.
| Lang | # Comp Sentences | Avg. Simp Sentences | Avg. Comp Length | Avg. Simp Length | Source Domain |
|---|---|---|---|---|---|
| English | 2500 | 2.86 | 24.35 | 17.23 | News |
| Sinhala | 2500 | 5.00 | 30.12 | 28.78 | Govt |
| Thai | 1499 | 5.06 | 48.24 | 37.77 | News |
| Tamil | 520 | 4.66 | 23.22 | 17.65 | Govt |
| Pashto | 2500 | 3.00 | 28.81 | 20.31 | Wiki |
Where open models stand today
The paper evaluates eight open-weight multilingual LLMs using SARI (the standard automatic metric for simplification, scoring three editing operations separately — the ADD / KEEP / DEL columns in the tables) and BERTScore (a semantic-similarity score).
The results have two layers. Few-shot examples (including a few demonstrations in the prompt) improve performance across nearly all languages, showing that style can be calibrated. But absolute performance on low-resource languages still clearly lags, especially when simplification requires adding suitable plain wording rather than only deleting material.
| Model | 0 Shot | 1 Shot | 5 Shot | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SARI Comp. | SARI | Fref | SARI Comp. | SARI | Fref | SARI Comp. | SARI | Fref | |||||||
| ADD | KEEP | DEL | ADD | KEEP | DEL | ADD | KEEP | DEL | |||||||
| Aya ✓ | 9.32 | 44.98 | 75.23 | 43.18 | 54.44 | 9.68 | 44.90 | 72.51 | 42.36 | 56.35 | 10.18 | 45.91 | 71.16 | 42.42 | 57.20 |
| Cmd-R ✓ | 9.69 | 44.95 | 72.89 | 42.51 | 55.90 | 10.99 | 43.71 | 77.57 | 44.09 | 55.03 | 11.91 | 45.28 | 77.09 | 44.76 | 56.63 |
| DeepSeek ✓ | 7.03 | 41.47 | 76.30 | 41.60 | 51.88 | 7.80 | 41.12 | 76.82 | 41.91 | 51.92 | 9.41 | 42.03 | 77.22 | 42.89 | 54.15 |
| EuroLLM ✓ | 9.32 | 45.60 | 68.36 | 41.10 | 56.98 | 10.99 | 46.98 | 69.35 | 42.44 | 57.96 | 11.63 | 46.55 | 70.93 | 43.04 | 58.10 |
| Gemma ✓ | 5.24 | 44.43 | 68.54 | 39.40 | 51.87 | 6.55 | 43.26 | 74.44 | 41.41 | 52.34 | 9.19 | 44.67 | 77.06 | 43.64 | 55.27 |
| LLaMA | 6.48 | 43.31 | 68.34 | 39.38 | 54.30 | 8.11 | 43.42 | 72.83 | 41.45 | 54.53 | 9.93 | 44.75 | 73.75 | 42.81 | 56.00 |
| Mistral ✓ | 8.56 | 43.66 | 77.46 | 43.23 | 52.49 | 10.31 | 43.82 | 78.43 | 44.18 | 54.55 | 11.61 | 44.01 | 78.59 | 44.74 | 55.89 |
| Qwen ✓ | 8.70 | 46.07 | 73.53 | 42.77 | 42.36 | 9.54 | 46.40 | 77.25 | 44.39 | 53.03 | 10.88 | 47.01 | 77.08 | 44.99 | 55.27 |
| Model | 0 Shot | 1 Shot | 5 Shot | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SARI Comp. | SARI | Fref | SARI Comp. | SARI | Fref | SARI Comp. | SARI | Fref | |||||||
| ADD | KEEP | DEL | ADD | KEEP | DEL | ADD | KEEP | DEL | |||||||
| Aya ✕ | 0.62 | 23.98 | 67.47 | 30.69 | 49.17 | 1.08 | 45.60 | 58.62 | 35.10 | 60.83 | 1.77 | 53.81 | 47.17 | 34.25 | 68.25 |
| Cmd-R ✕ | 0.75 | 50.82 | 51.73 | 34.44 | 61.91 | 0.93 | 54.41 | 44.44 | 33.26 | 67.84 | 0.70 | 56.53 | 35.62 | 30.95 | 70.52 |
| DeepSeek ✕ | 0.52 | 41.19 | 60.71 | 34.14 | 38.65 | 0.90 | 48.83 | 54.59 | 34.78 | 63.65 | 0.91 | 50.16 | 52.51 | 34.53 | 66.26 |
| EuroLLM ✕ | 0.50 | 54.28 | 44.40 | 33.06 | 67.55 | 0.65 | 54.87 | 43.28 | 32.93 | 69.72 | 0.78 | 55.37 | 42.09 | 32.75 | 70.42 |
| Gemma ✕ | 3.84 | 25.08 | 70.78 | 33.23 | 56.95 | 4.47 | 34.75 | 68.57 | 35.93 | 61.47 | 5.39 | 46.39 | 61.95 | 37.91 | 66.04 |
| LLaMA ✕ | 0.70 | 18.34 | 70.28 | 29.77 | -22.40 | 3.15 | 46.28 | 61.67 | 37.04 | 51.15 | 1.96 | 46.53 | 58.15 | 35.55 | 33.03 |
| Mistral ✕ | 0.94 | 26.36 | 68.13 | 31.81 | 47.73 | 1.42 | 41.20 | 63.04 | 35.22 | 61.31 | 1.51 | 45.93 | 58.60 | 35.35 | 64.40 |
| Qwen ✕ | 2.34 | 47.48 | 58.92 | 36.25 | 58.02 | 2.81 | 49.88 | 55.34 | 36.01 | 64.76 | 2.62 | 53.79 | 48.71 | 35.04 | 65.57 |
- Multiple references matter.A single target underestimates the space of acceptable simplifications.
- Few-shot helps but does not solve the gap.Examples calibrate style without erasing resource imbalance.
- ADD is hardest.Models can delete redundant content, but low-resource languages make helpful additions difficult.
A reminder for multilingual AI
Download the dataset
The project page hosts the data and evaluation details for multilingual NLP and accessibility research.