The same chess position can be drawn as a board or written as one line of notation; the same molecule can be a structural drawing or a string of characters. The information is identical — only the format differs. We assume an AI model that reads both images and text will give the same answer either way. SEAM measures this directly, and today that assumption does not hold.
Change the format, change the answer
Large models that handle both images and text are called vision-language models (VLMs). In demonstrations they read charts and answer questions about documents, often impressively. But trusting such a system requires something more basic: given the same information, the conclusion should not depend on whether it arrived as a picture or as text. An assistant whose answer changes with the file format is not one you can rely on.
Most earlier multimodal tests put text inside screenshots — OCR-style tests (OCR: extracting text from images) that cannot tell whether a model fails to see the image or fails to understand the question. SEAM turns “same semantics, different modality” into a controlled experiment: every question exists as a text version, an image version, and a side-by-side version, and the model answers under all three conditions for comparison.
Equivalent notations from four domains
The key to the control is equivalence. SEAM picks four domains that naturally have both a mature text notation and a visual form: chess has FEN (a standard one-line encoding of a full board position) and board diagrams; chemistry has SMILES (a string notation for molecular structure) and molecule drawings; music has ABC notation (a letter-based text format for scores) and sheet music; graph theory has adjacency matrices (tables recording which nodes connect) and node-edge diagrams. In each domain, text and image are native representations carrying strictly the same information.
Any performance difference constructed this way can only come from how the model handles the representation, never from task difficulty.
| Domains | Chess · Chemistry · Music · Graph theory |
| Tasks | 16 tasks, four per domain |
| Items | 3,200 base questions; 9,600 evaluations across text, vision, and text+vision |
| Models | 21 contemporary VLMs, proprietary and open-source |
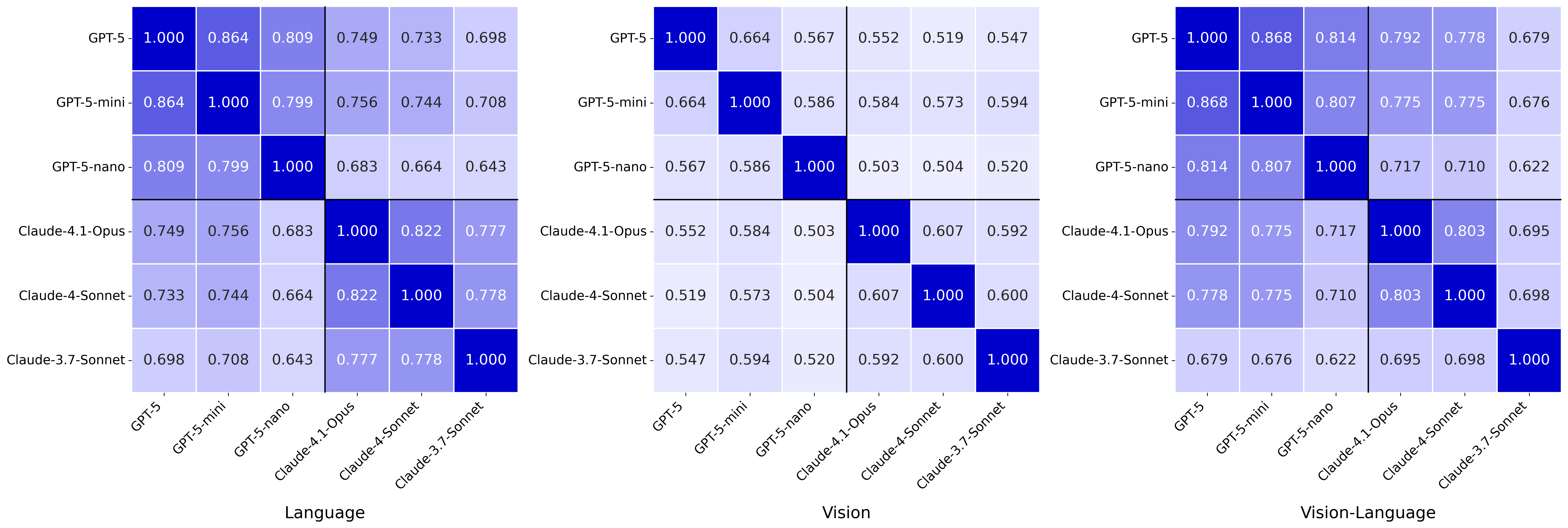
Measuring consistency across 21 models
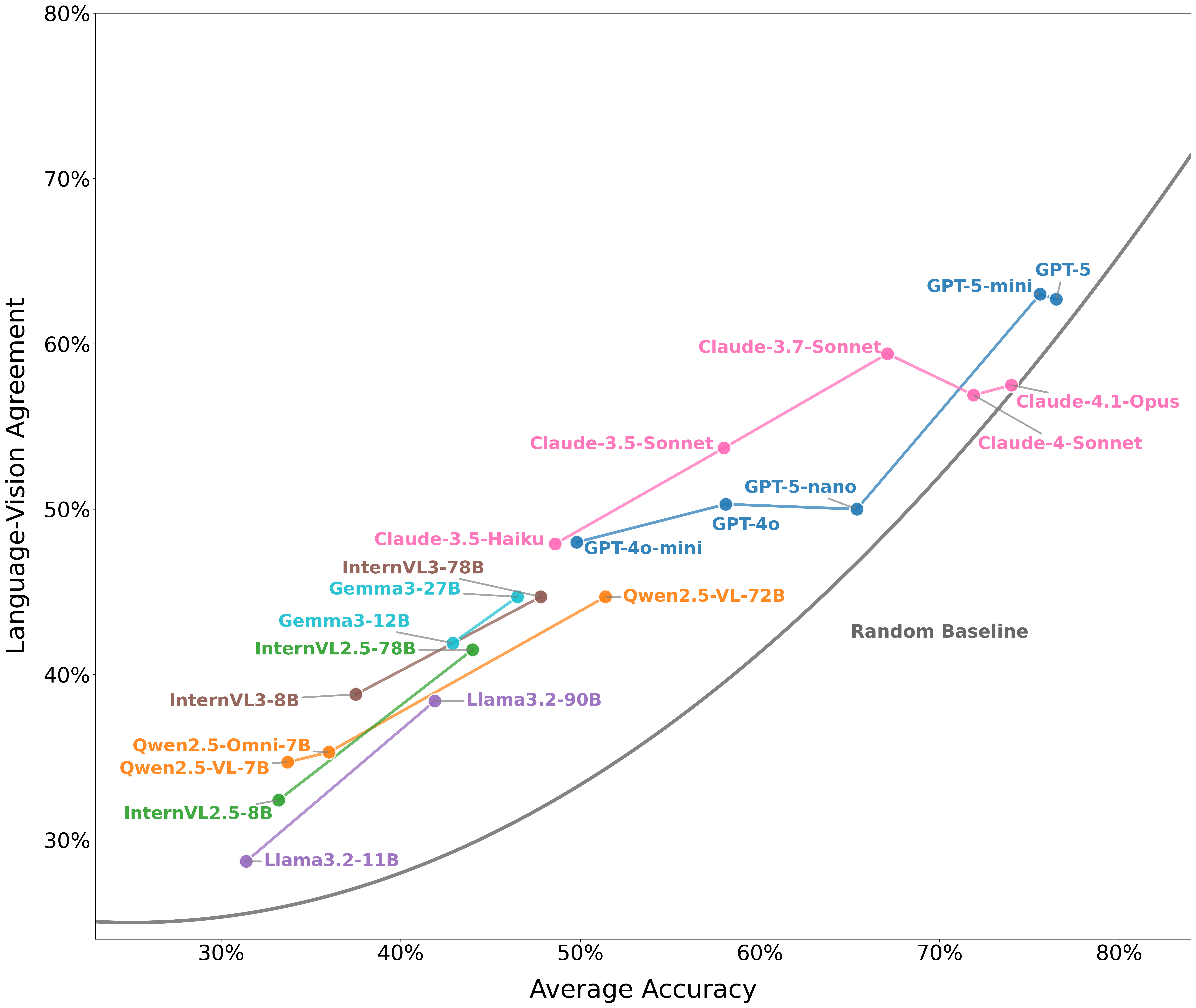
All 9,600 evaluations cover 21 contemporary VLMs, proprietary and open-source. The overall pattern is clear: models are usually stronger on the text side and noticeably weaker on the visual side. More striking, the same model frequently gives different answers to the text and image versions of the same question — a sign that stable cross-representation reasoning has not yet emerged.
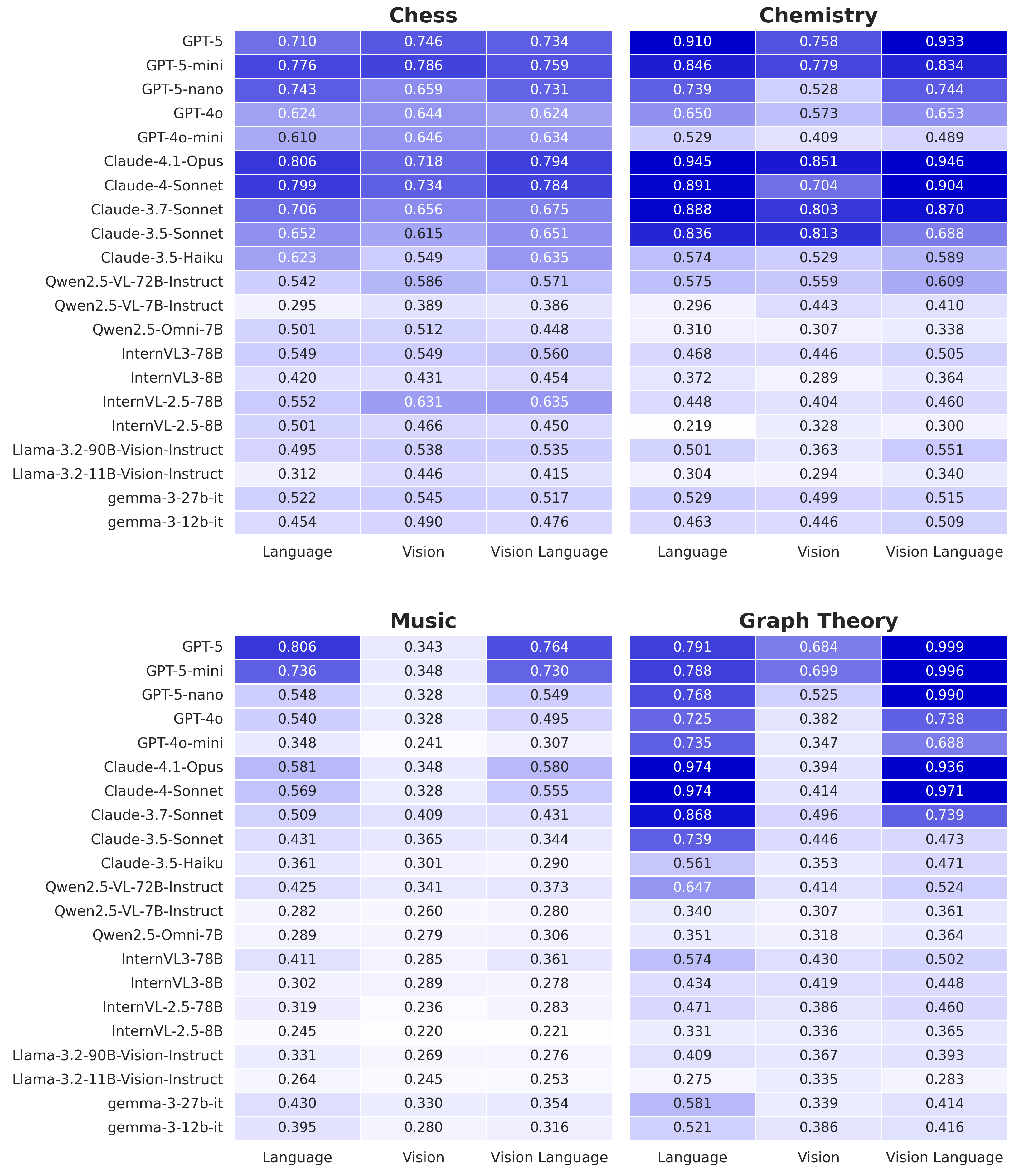
- Vision often trails language.Even when information is equivalent, the visual channel loses accuracy.
- Agreement does not appear on its own.Changing the representation can change the answer.
- Failures are diagnosable.Text-side errors often involve symbol parsing; vision-side errors often hallucinate structure — the model “sees” pieces, bonds, or edges that are not in the image.
A new axis for multimodal evaluation
Open the dataset and leaderboard
SEAM releases code, data, and a leaderboard so teams can track consistency over time.