When a model gets something wrong and you ask it to double-check, it usually repeats itself — or talks itself out of a correct answer. ThinkTwice starts from that observation: if taking a second look is a skill, can it be trained directly? The experiments answer yes: no extra supervision signal, about 3% additional training cost, and an 11.5-point gain on competition math.

Why “check your work” rarely works
The dominant way to train reasoning models today is RLVR (reinforcement learning with verifiable rewards — scoring only whether the final answer is right): the model solves large volumes of math and code problems, earning reward when the answer checks out. This steadily sharpens the model’s first attempt, which is why competition-math scores have risen so quickly.
But nowhere in that process does the model practice reviewing itself. It has seen millions of first-pass solutions and almost no examples of taking its own answer and making it right. It is much like a student who only grinds through problem sets and never checks their own paper: told to “look it over again” in the exam hall, they mostly just copy out the same answers. Hence the scene above: asked to double-check, the model either repeats its previous answer or rewrites it with no sense of direction.
Existing remedies mostly require extra resources: a separately trained critic model that spots errors, process rewards that grade every reasoning step, or human-written critique data. ThinkTwice takes a different route: introduce no new signal, and let the model practice both behaviors — solving and self-correcting — under the same right-or-wrong reward.
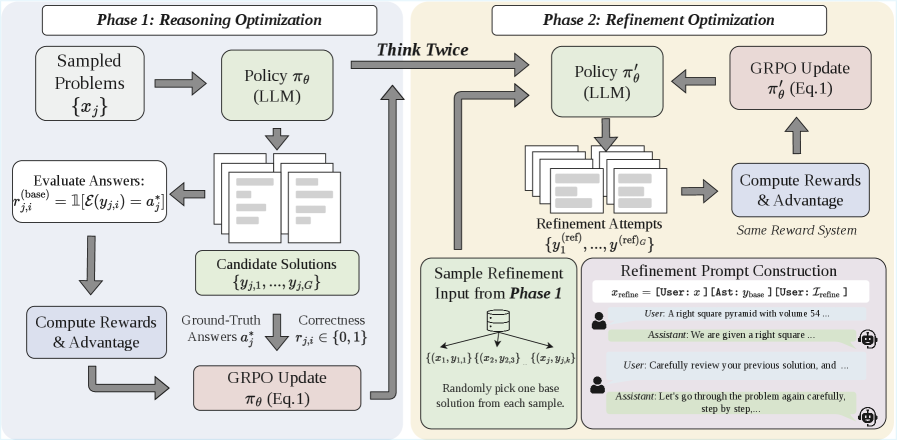
One reward, two behaviors
Training steps come in pairs. The first step is standard GRPO (a widely used RLVR algorithm: sample several solutions to the same problem and update the model on their relative quality within the group). The model produces several solutions and receives a binary correctness reward — right or wrong, no partial credit.
The second step hands those solutions back to the model, asks it to refine them, and applies the same reward to the result. The reward function never changes; what changes is that it now covers both solving and fixing. The whole pipeline needs no critic model, no process reward, and no human critique data, at about 3% extra training cost.
Evidence across five math benchmarks
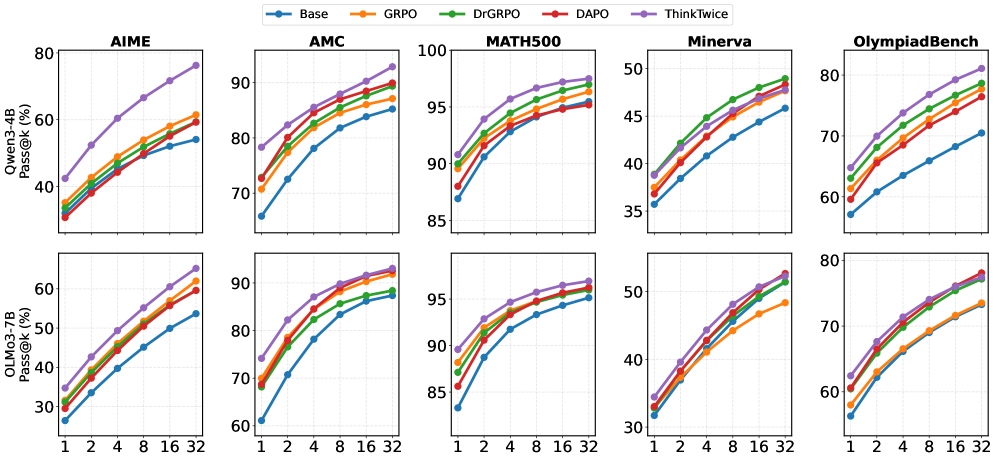
Experiments cover five math benchmarks — MATH500, AIME 2024, AMC, Minerva Math, OlympiadBench — and two model families, Qwen3-4B and OLMo-3-7B. The representative result is Qwen3-4B on AIME 2024, measured as pass@4 (four attempts allowed; any correct one counts):
| Setting | AIME pass@4 gain |
|---|---|
| Single-pass GRPO | baseline |
| ThinkTwice, no refinement at inference | +5.0 |
| ThinkTwice, one refinement pass | +11.5 |
The two layers of improvement come from different places. Even with refinement never invoked, the ThinkTwice-trained model answers 5.0 points above the baseline on its first attempt — practicing correction improves first-pass solving. Invoking one refinement pass brings the total gain to 11.5 points.
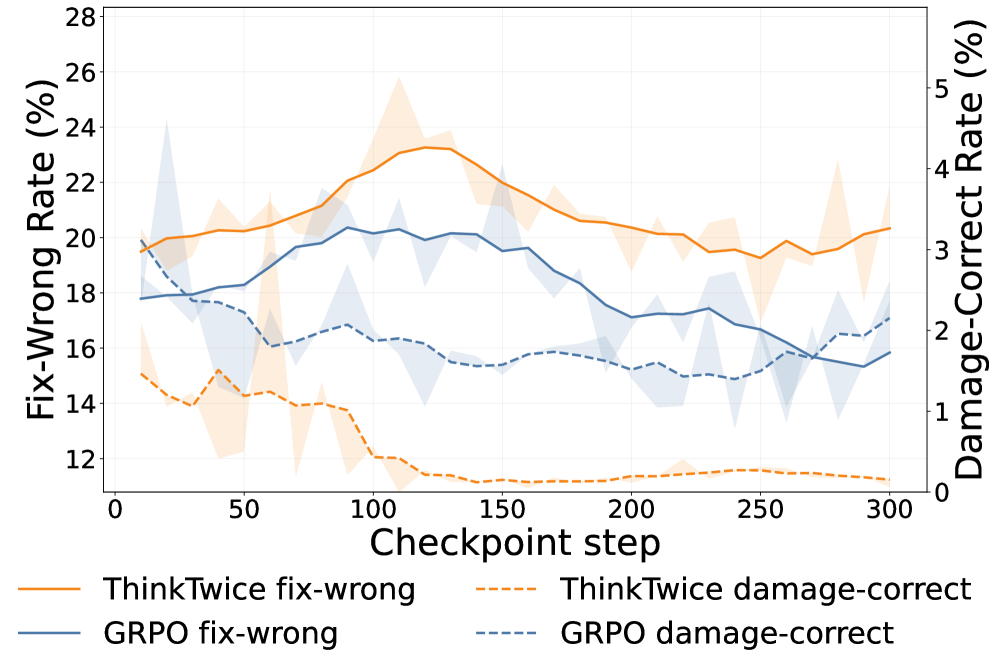
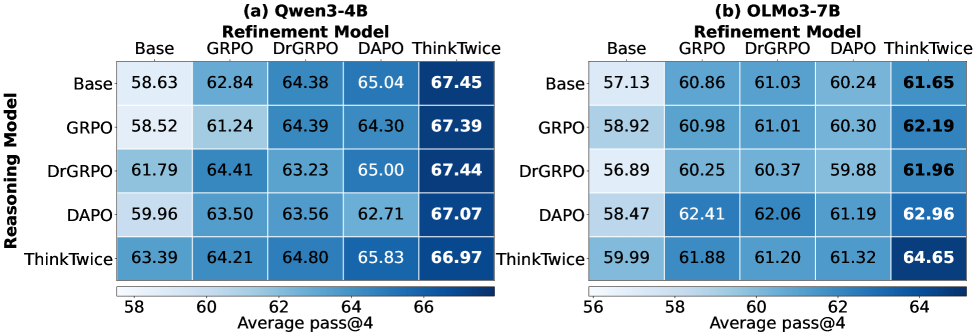
Training also reveals an interesting dynamic: the model first learns to turn wrong answers into right ones, then gradually learns to preserve answers that are already correct — an implicit curriculum nobody designed. The refinement skill transfers across models, too: it fixes other models’ solutions just as well, suggesting it has learned more than its own output style.
What it suggests for reasoning training
Open the paper and code
ThinkTwice code and paper links are available for reproduction or adaptation to other verifiable tasks.