
AtomHub 是你一直想招的那个 AI 见习生:读懂任务、找出资料、填好表格、调用合适的工具,最后把一份你可以直接编辑的初稿交给你。聊天框背后是一套多智能体运行时——把一次请求拆成多个并行子任务再合并结果,让你不再在标签页之间反复粘贴。
大体量文档处理
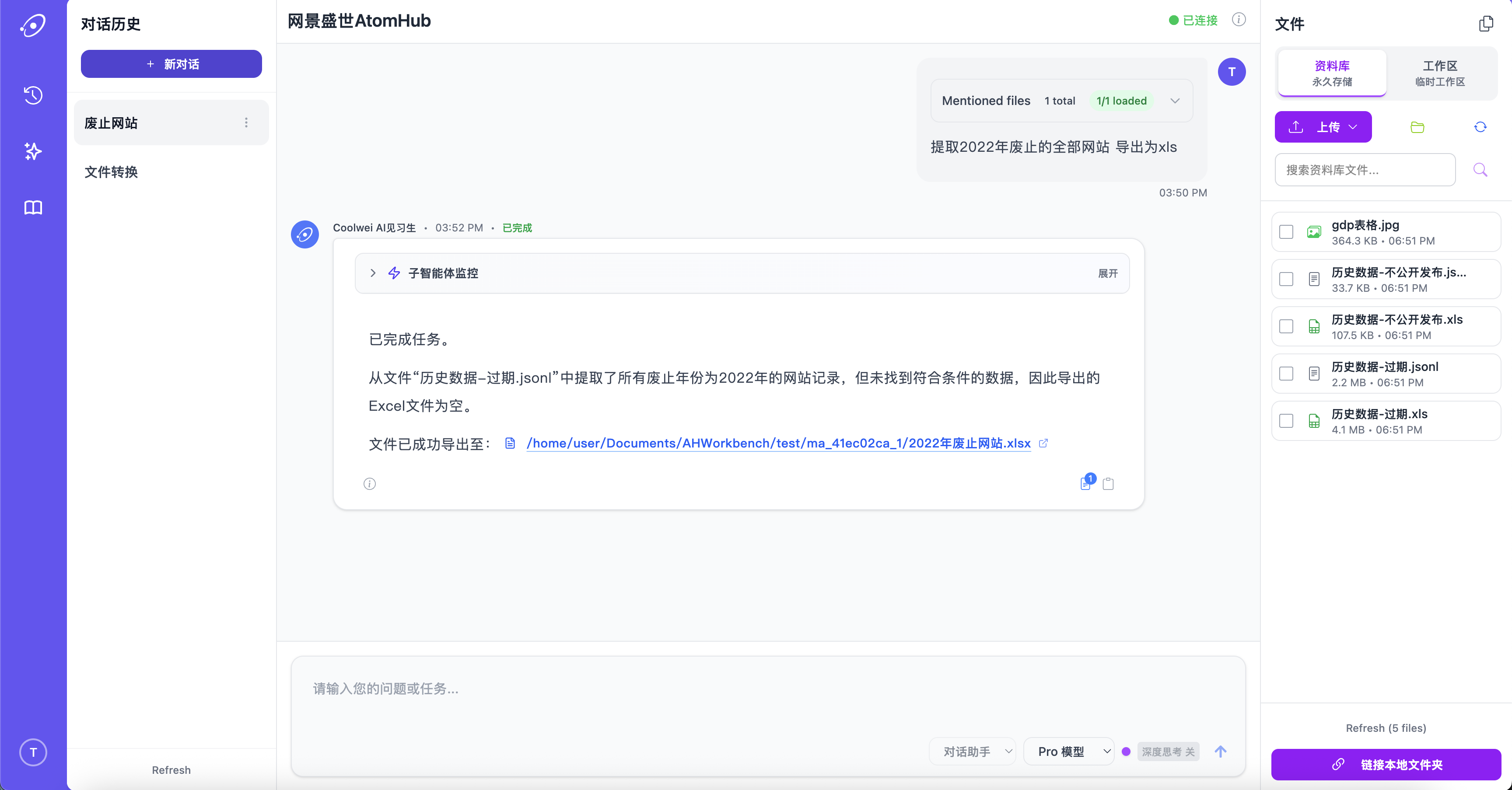
把 PDF、幻灯片、电子表格、转录稿丢进来——AtomHub 并行解析、建索引、推理。长上下文检索叠加缓存的工作记忆,让追问不必重读语料。
面向分析师工作流:从一份 200 页报告里抓数字、对账两份来源、总结季度环比变化。
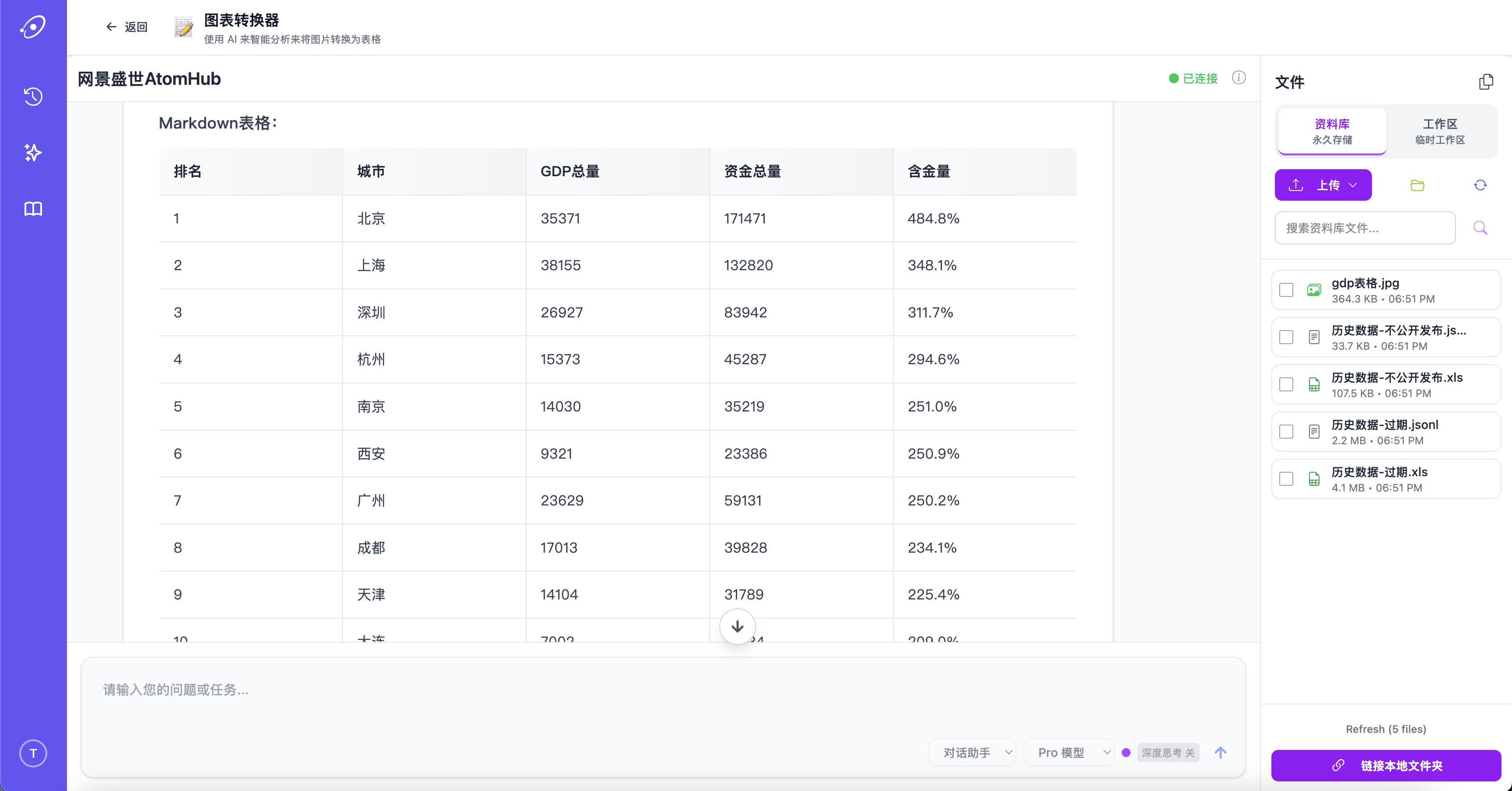
图表和表格,不只是文字
AtomHub 把扫描表格、截图图表、图片表单转成可直接计算的结构化数据。表头与单位被保留下来,结果是一张电子表格,而不是一段堆砌的文字。
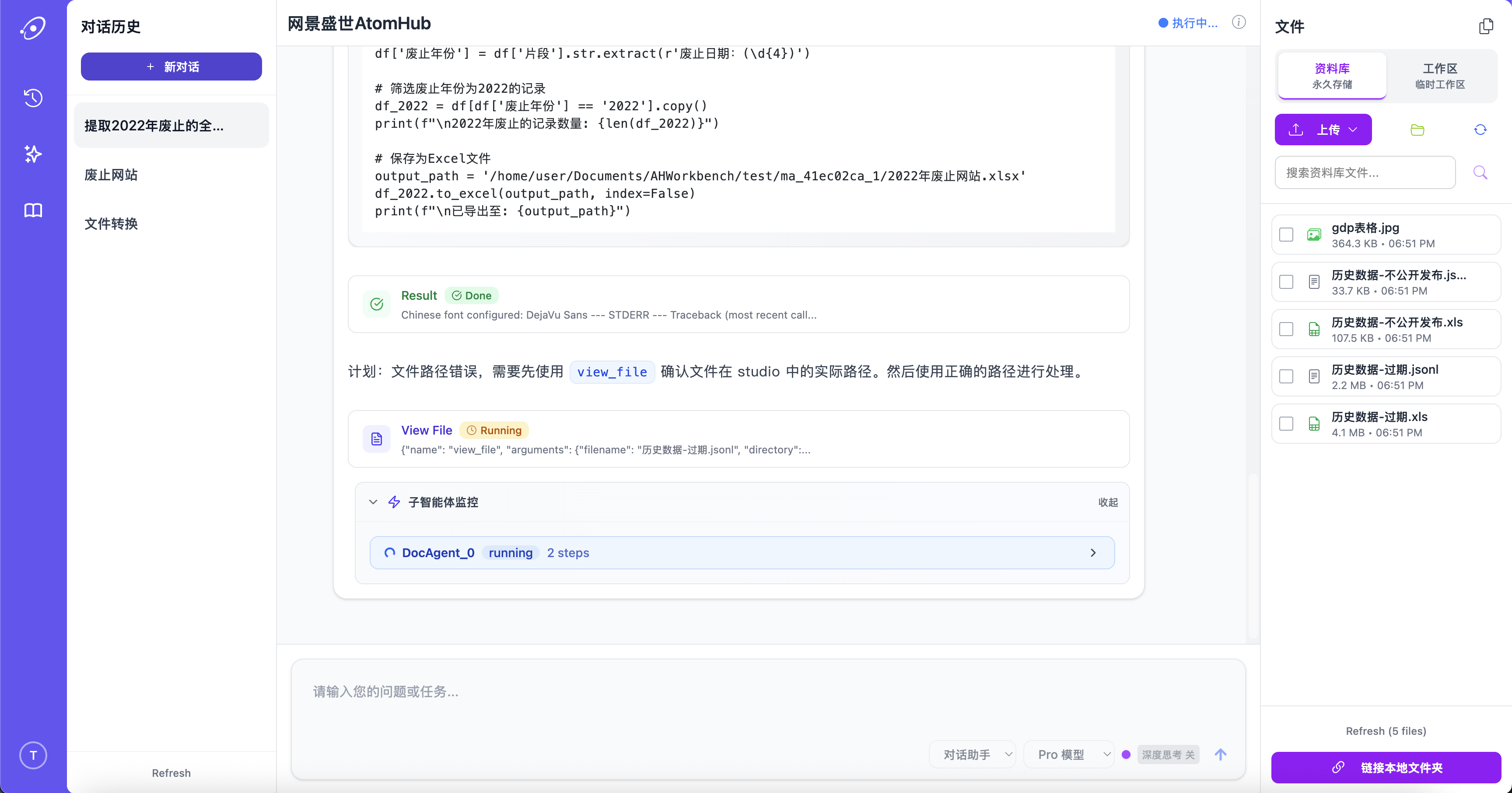
能真正运行的工具调用
AtomHub 通过有类型的工具接口与你的数据库、API、内部服务对话。它不只建议 SQL——它执行查询、读取结果、决定下一步,并展示每一步的过程。
自定义工具可以在几分钟内注册;权限按智能体与工作区分级管理。
架构亮点
多智能体编排
一次请求扇出到多个专长智能体并行工作,再由协调智能体把结果合成答案。
多模态搜索
一次查询同时搜索文字、表格、图表、音频转录与图像,结果跨格式统一呈现。
本地数据接入
对接本地数据库、文件共享与私有 API。数据不必离开你的网络。
双层记忆库
工作区记忆跨会话保留,任务记忆只属于单次工作。两者皆可检视、可编辑。
三层缓存
提示级、检索级、工具结果级缓存——让重复工作既快又省。
嵌入既有工作流
通过 webhook、MCP 或 SDK 直接接入既有工作流——不要求你迁移。
它是怎么工作的
每次请求先进入一个规划智能体,由它拆解任务、把子任务分发给检索、代码执行、工具调用、摘要等专长智能体。能并行的并行执行,必须按序执行的依赖被显式追踪。一个协调智能体审查中间结果、必要时向你提澄清问题,最后产出最终答复。
这层编排之下,是三层架构:多模态感知层把所有输入归一到统一表示;多路处理层包含中央词库、自定义词库与纠错模型;后处理整合层在结果送达之前把子结果合并。