
10×准确率提升——误报率从 5% 降至 0.5%
15×速度提升——2,000 → 30,000 字/秒
10×成本降低——H100 级降至 4090 级
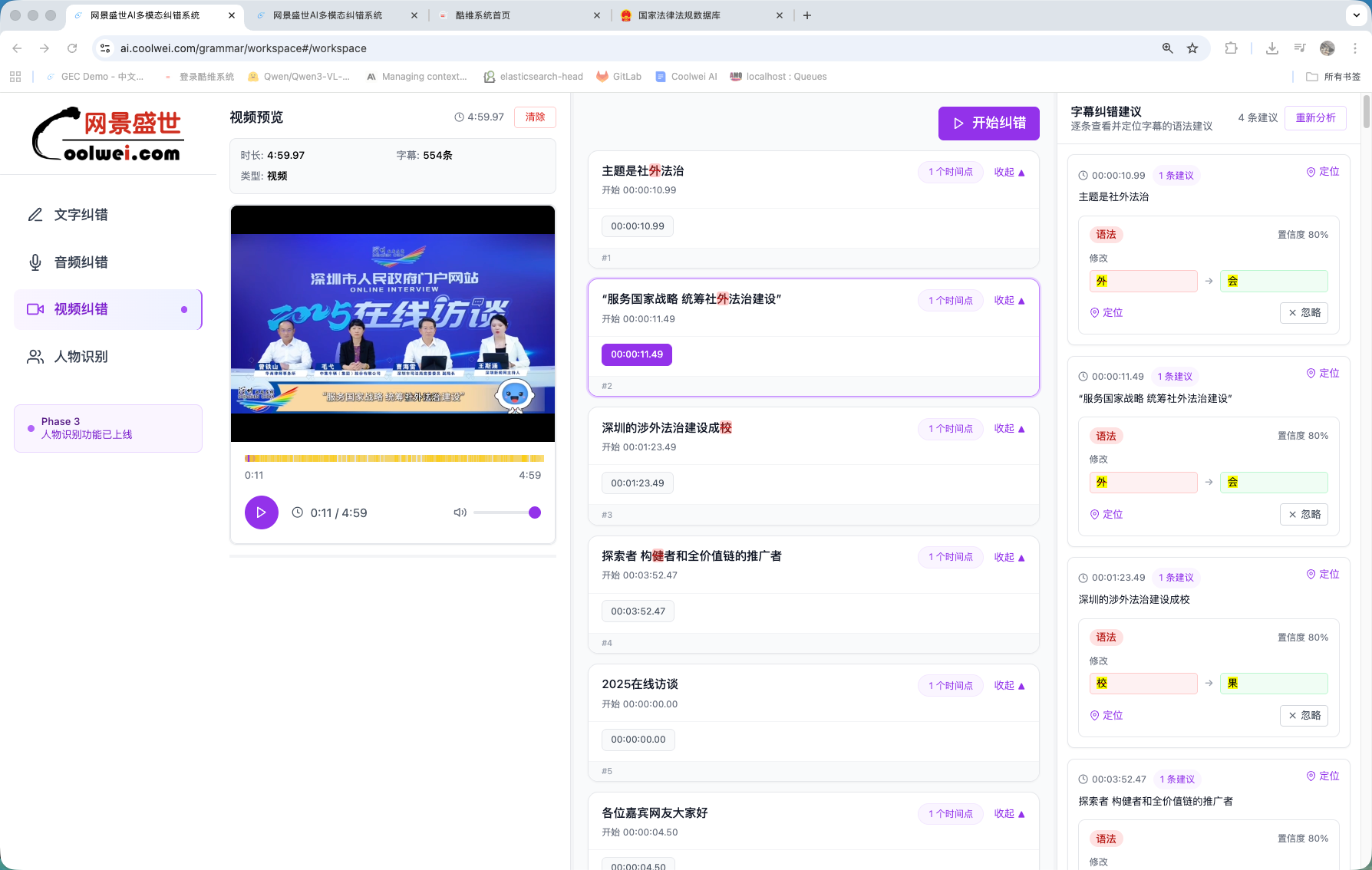
99%+视频字幕纠错准确率
言澜是一个用多阶段强化学习训练的中文语法纠错模型,核心优化目标来自生产部署的真实约束:低到不浪费编辑时间的误报率、能接日级新闻流水线的吞吐量、以及一张中端 GPU 就能跑得动的成本曲线。模型不仅处理纯文本,也读视频字幕、音频转录与图片 OCR——纠错发生在内容真正生成的地方。
视频字幕纠错
把言澜接入字幕流水线,每一行都被即时审一遍——错别字、识别错的字符、术语不一致——准确率 99%+,每分钟视频耗时 1–5 秒。已用于日更多语言字幕的编辑团队。
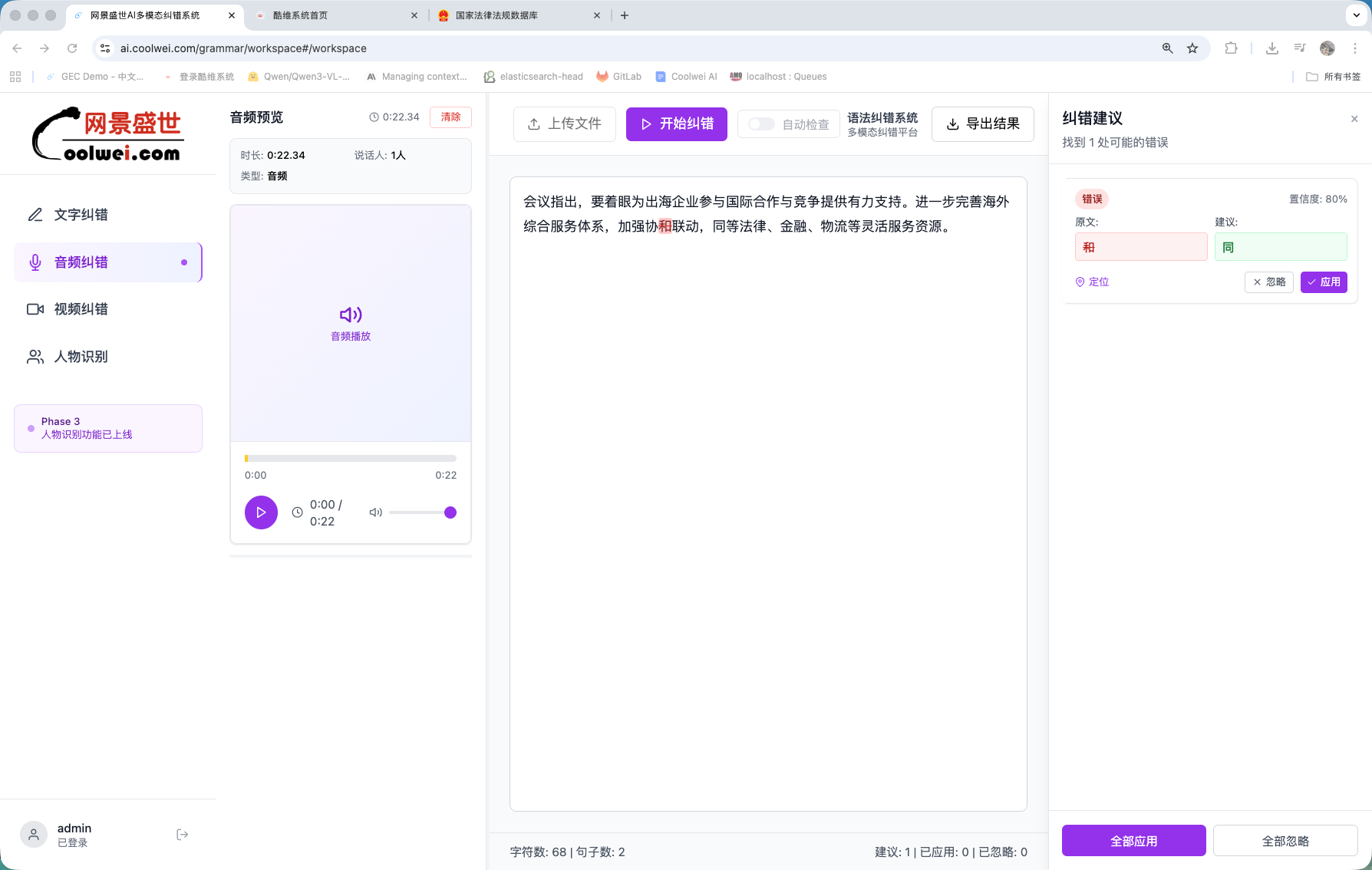
音频转写纠错
ASR 转录稿往往噪声很大。言澜结合音频上下文阅读它——修正听错的同音字、规范专有名词、保留方言形式而不是把它们抹平。在主流普通话变体上达到 96%+ 准确率。
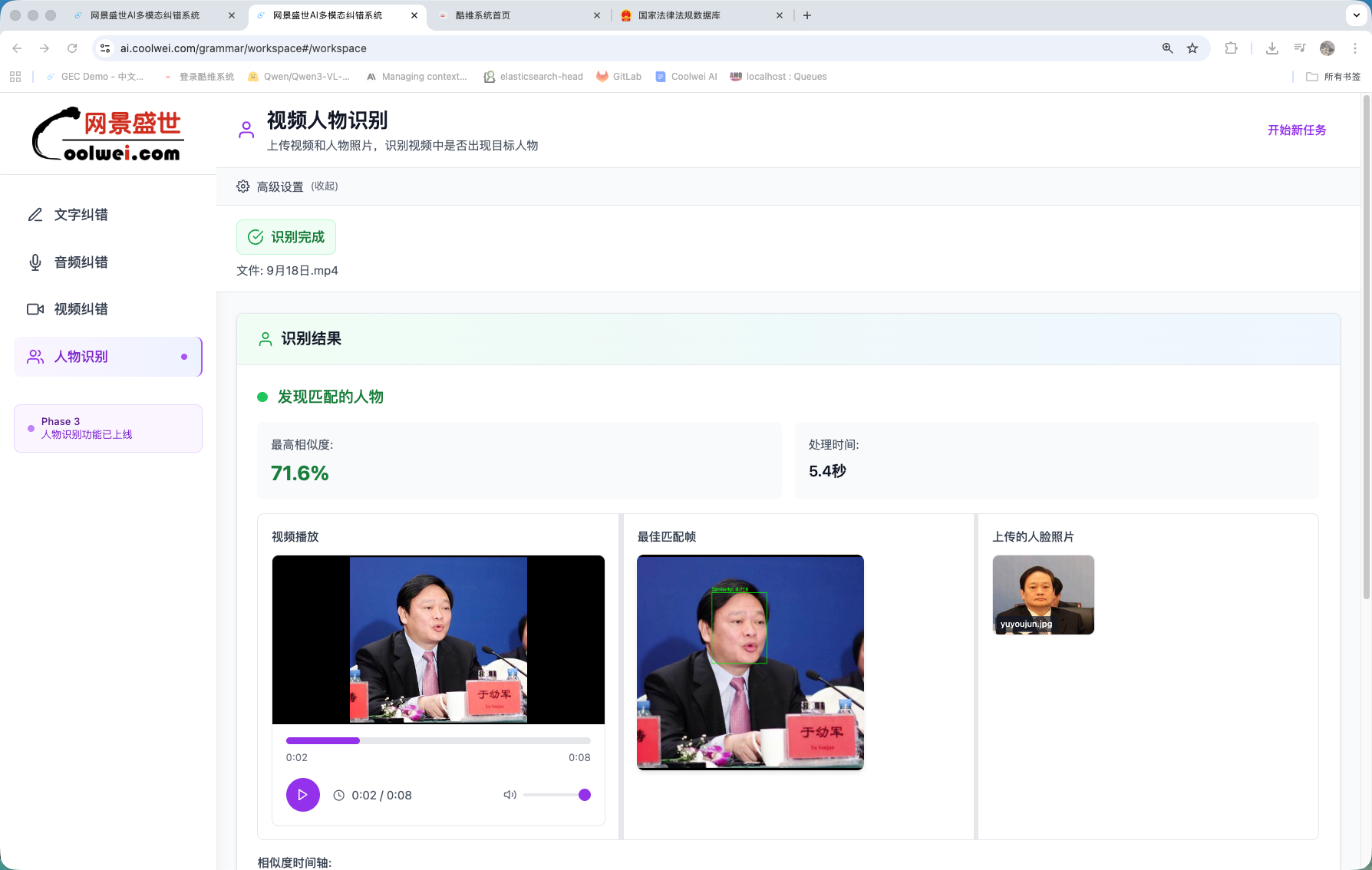
人脸识别检测
不止文字:言澜带一个为广播与流媒体合规审核训练的人脸核验头。识别准确率 98%+,比人工审核流水线 提速 20–30 倍。
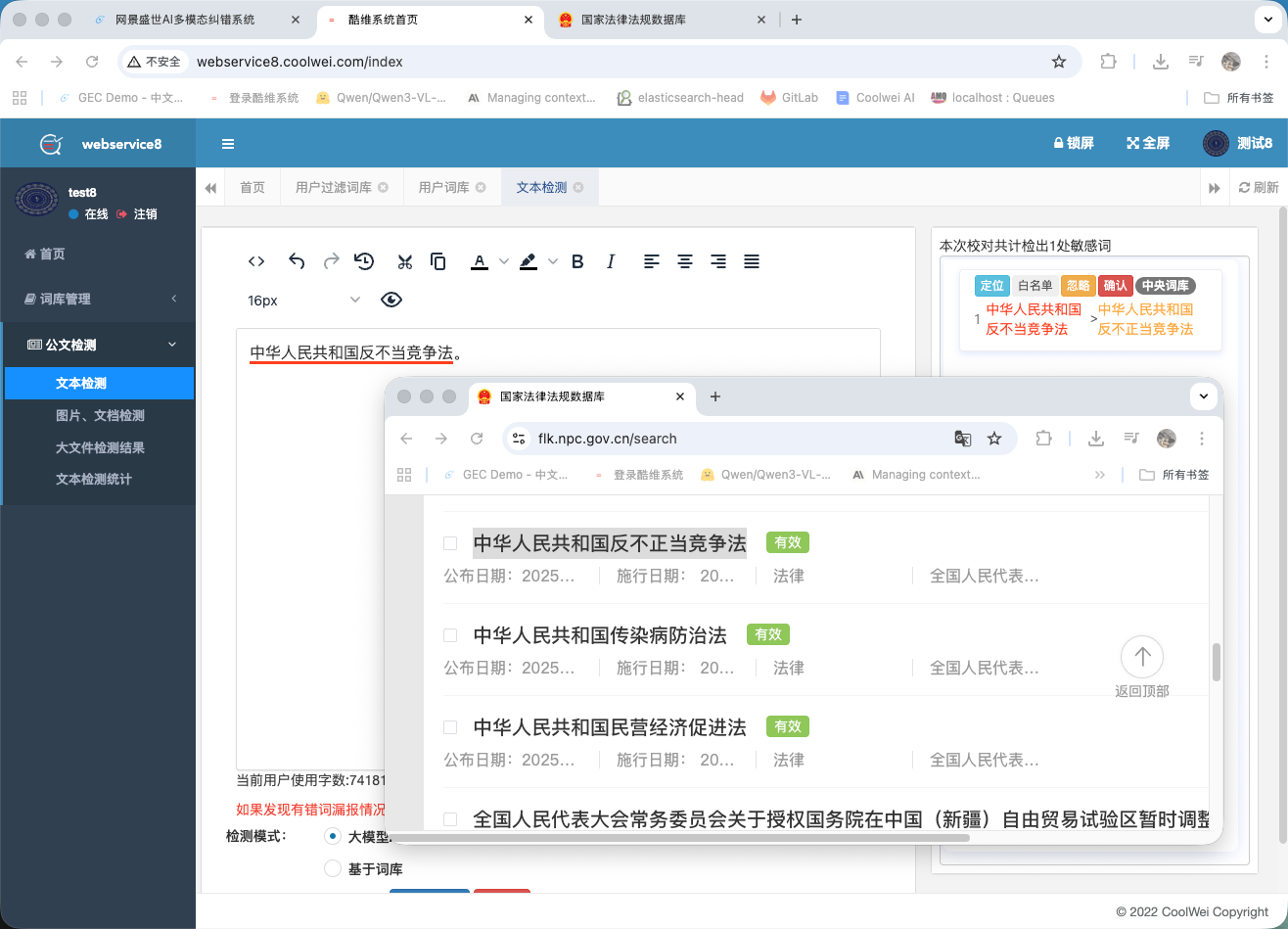
法规合规检测
对接 16,740 部中国法律法规语料库,每日自动更新。言澜可标记出与现行法规冲突的内容——适用于政府、媒体、教育内容的法务复核。
性能:与显而易见的基线对比
下表为言澜在内部中文 GEC 评测集上的表现,与目前能找到的最强商用基线一对一对比。三个指标缺一不可——只准但慢的模型上不了线;只快但贵的模型撑不过财务复核。
| 指标 | 言澜 | 最佳基线 | 提升 |
|---|---|---|---|
| 误报率 | 0.5% | 5% | 10× |
| 吞吐量(字/秒) | 30,000 | 2,000 | 15× |
| 部署 GPU 等级 | RTX 4090 | H100 | 10× 成本 |
它是怎么工作的
言澜以一层多模态感知把文本、音频、图像、视频字幕统一成同一种 token 流,再通过一个分类器在标准中文中央词库、按部署调优的自定义词库与纠错模型之间路由。最后由后处理整合层把结果合并输出。
训练是多阶段强化学习:先在人工校对过的纠错样本上做监督微调,再用编辑奖励做强化学习,并显式地惩罚误报——这一步是把误报率压到 0.5% 的关键。