国际象棋引擎的棋力超过人类世界冠军已有多年,但问一句“这步为什么最好”,它只会给出一个评估数值。人类教练会讲解,大模型也健谈,可一到具体棋局就频频出错。Grounded Chess Reasoning 研究的正是这道沟:能否让一个 4B 的小模型,既像引擎一样下对,又像教练一样讲清?
引擎会下棋,但讲不出道理
这道沟并非棋类独有。许多专业领域都有“算得准但不会教”的专家系统(solver——能给出确定正确答案的专家程序):它们给出的答案可靠,却无法用人类语言解释依据。就像一位手艺顶尖的老师傅,活儿做得无可挑剔,却说不清“为什么要这么做”,徒弟在旁边看十年也学不会。把专家系统的确定性知识,翻译成人能读懂、模型能学习的推理,是一个相当普遍的问题。
国际象棋恰好是研究这个问题的理想试验场。棋题有唯一的最佳首步,对错可以由引擎即时验证;与此同时,棋类推理对大模型并不友好——直接做 RLVR(可验证奖励强化学习——只按最终答案对错给分),训练几乎无法启动。难度与可验证性的组合,让 chess 成为检验“先蒸馏专家过程、再用可验证奖励强化”的合适场景。
大师蒸馏:把专家知识翻译成推理
大师蒸馏(Master Distillation)把两类系统组合起来:Stockfish(最强的开源国际象棋引擎,棋力远超人类冠军)提供确定性真值——哪一步是最佳着法;Gemini-3-Flash 把引擎的判断口语化,写成自然语言推理轨迹;4B 参数的学生模型 C1 再向这些轨迹学习。
训练分两个阶段。第一阶段在口语化专家轨迹上做监督微调(SFT——用示范文本直接教模型模仿);第二阶段用可验证奖励做 RLVR 强化。顺序很重要:跳过第一阶段直接强化学习基本无效——基座太弱时奖励信号无从放大,这正是所谓的冷启动问题。SFT 先把能力种进去,RLVR 才有信号可以放大。
训练数据的构成同样讲究。棋题的主题分布天然失衡,常见战术主题会淹没稀有主题;论文用主题均衡采样(算法 1)保证稀有主题在训练数据中占有一席之地。
- 统计每个主题 t 的频率:f(t) ← |{p ∈ D : t ∈ T(p)}|
- 选出最稀有的 K 个主题:Trare ← arg minK f(t)
- 初始化已选棋题 ID 集合:S ← ∅
- 初始化输出:Dbal ← ∅
- for 每个主题 t ∈ Trare do
- 取候选集 Ct ← {p ∈ D : t ∈ T(p) ∧ id(p) ∉ S}
- 从 Ct 中无放回采样 min(M, |Ct|) 道棋题
- 并入输出:Dbal ← Dbal ∪ 采样所得棋题
- 登记已选 ID:S ← S ∪ {id(p) : p ∈ 采样所得棋题}
- end for
- return Dbal
一个 4B 模型的成绩
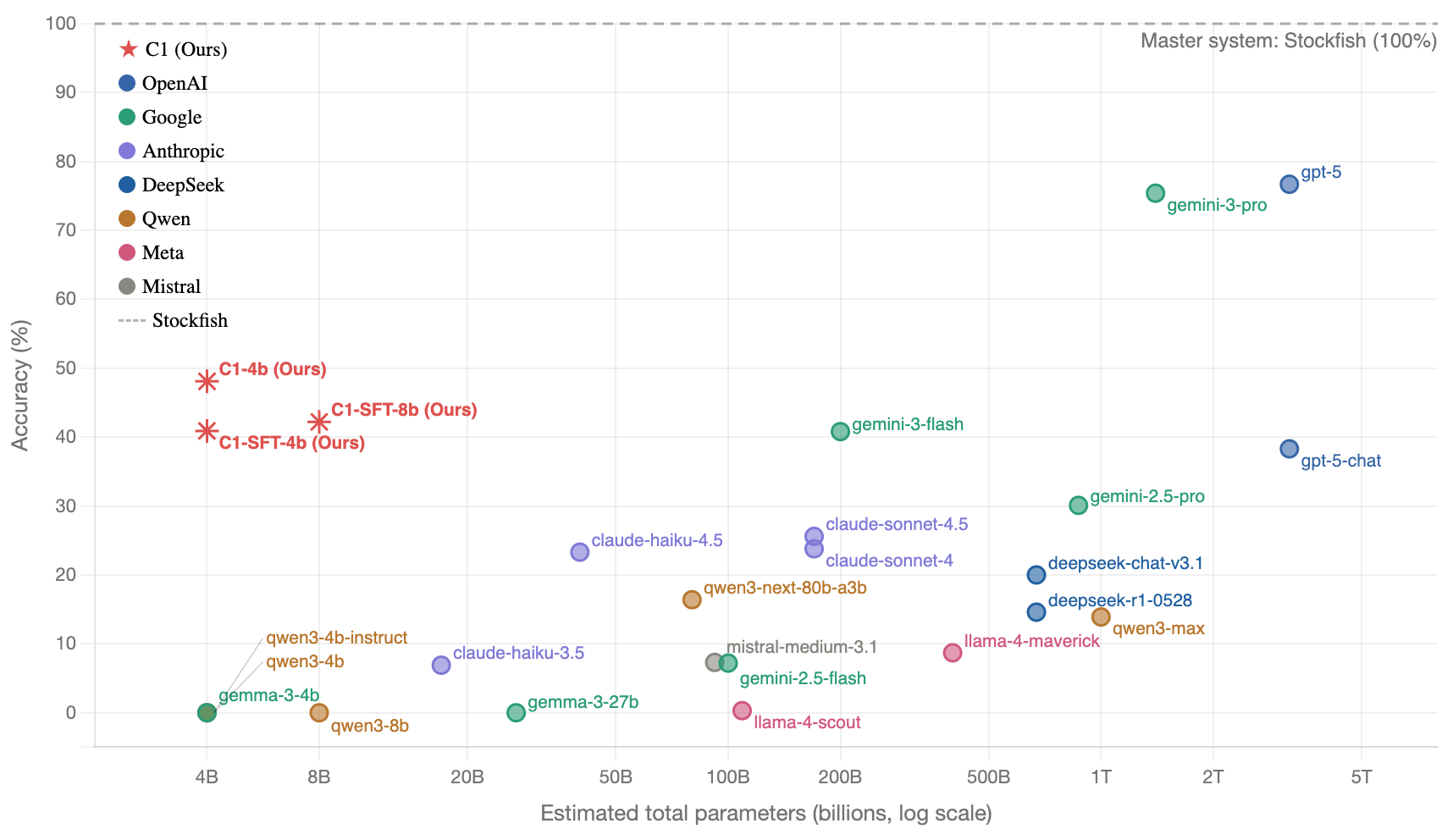
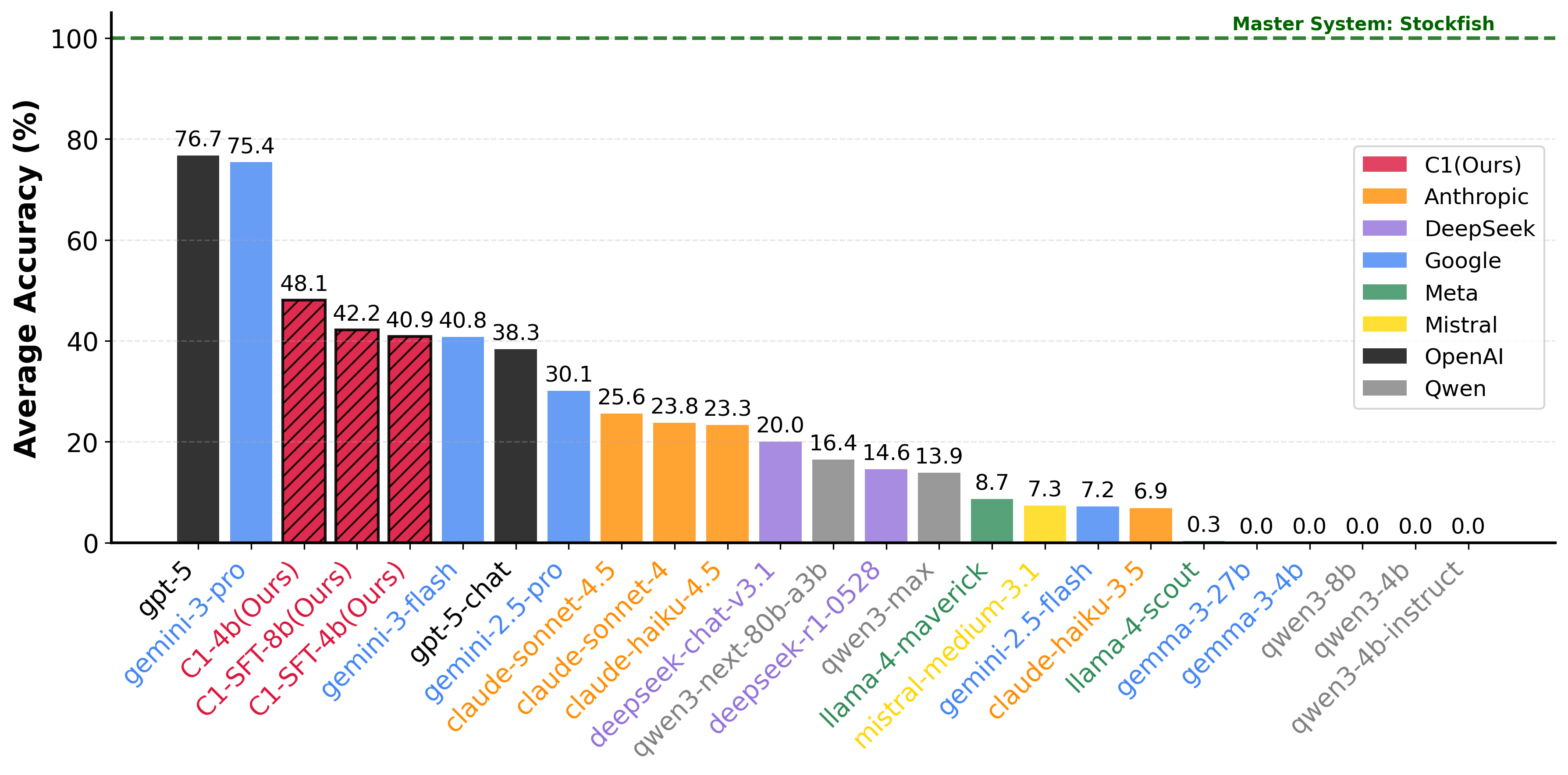
在主题均衡的评测集上,C1-4B 取得 48.1% 的棋题准确率,超过表中多数前沿大模型,也超过为它生成训练轨迹的 Gemini-3-Flash(40.8%)。强化阶段在 SFT 基础上再提升 7.2 个百分点。
| Model | Beginner | Intermediate | Advanced | Expert | Theme-Split | Avg Acc | Avg Tokens |
|---|---|---|---|---|---|---|---|
| gpt-5 | 95.0 | 84.0 | 54.0 | 31.0 | 85.2 | 76.7 | 12,193 |
| gemini-3-pro | 88.0 | 86.0 | 70.0 | 44.0 | 78.2 | 75.4 | 3,182 |
| gemini-3-flash | 65.0 | 59.0 | 34.0 | 19.0 | 38.0 | 40.8 | 6,418 |
| gpt-5-chat | 52.0 | 39.0 | 27.0 | 18.0 | 41.8 | 38.3 | 925 |
| gemini-2.5-pro | 37.0 | 31.0 | 29.0 | 19.0 | 31.0 | 30.1 | 9,668 |
| claude-sonnet-4.5 | 32.0 | 29.0 | 15.0 | 11.0 | 28.6 | 25.6 | 3,227 |
| claude-sonnet-4 | 35.0 | 19.0 | 16.0 | 10.0 | 26.8 | 23.8 | 8,028 |
| claude-haiku-4.5 | 33.0 | 24.0 | 14.0 | 11.0 | 25.6 | 23.3 | 8,111 |
| gemini-2.5-flash | 9.0 | 4.0 | 6.0 | 5.0 | 8.2 | 7.2 | 9,991 |
| deepseek-chat-v3.1 | 27.0 | 21.0 | 6.0 | 16.0 | 22.0 | 20.0 | 11,249 |
| qwen3-next-80b-a3b | 24.0 | 14.0 | 14.0 | 8.0 | 17.6 | 16.4 | 13,938 |
| deepseek-r1-0528 | 11.0 | 10.0 | 14.0 | 16.0 | 16.0 | 14.6 | 14,442 |
| qwen3-max | 22.0 | 15.0 | 3.0 | 16.0 | 13.8 | 13.9 | 3,393 |
| llama-4-maverick | 12.0 | 8.0 | 5.0 | 10.0 | 8.6 | 8.7 | 1,092 |
| mistral-medium-3.1 | 9.0 | 6.0 | 7.0 | 4.0 | 8.0 | 7.3 | 2,818 |
| llama-4-scout | 0.0 | 0.0 | 0.0 | 1.0 | 0.4 | 0.3 | 806 |
| gemma-3-27b | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 705 |
| C1-SFT-4B | 51.0 | 30.0 | 30.0 | 26.0 | 46.2 | 40.9 | 188 |
| C1-SFT-8B | 57.0 | 36.0 | 27.0 | 27.0 | 46.6 | 42.2 | 189 |
| C1-4B | 65.0 | 39.0 | 39.0 | 22.0 | 53.6 | 48.1 | 178 |
输出长度同样值得注意:C1 平均每题约 178 个 token(token——模型输出文本的计量单位,约合半个到一个词),比推理型大模型短约两个数量级,更接近人类棋手用两三句话讲清一步棋的方式。消融实验(Table 2)还显示,数据规模与主题均衡都对最终能力有实质影响。
| Scale | Distribution | Quality | Context | SFT |
|---|---|---|---|---|
| 8k | random | flash | full | 19.3 |
| 8k | hard | flash | full | 16.2 |
| 8k | balanced | pro | full | 22.8 |
| 8k | balanced | flash | full | 20.1 |
| 16k | balanced | flash | full | 29.7 |
| 8k | balanced | flash | Multi PVs | 17.6 |
| 8k | balanced | flash | w/o Theme | 17.3 |
| 8k | balanced | flash | w/o Feigned | 16.3 |
| 39k | balanced | flash | full | 40.9 |
- 小模型,强推理。4B 模型达到 48.1% 主题均衡棋题准确率。
- 解释更像人类棋手。平均输出约 178 token,比推理型大模型短两个数量级。
- 学生可以超过表达者。Stockfish 的真值与 RLVR 的奖励共同让 C1 超过 Gemini-3-Flash。