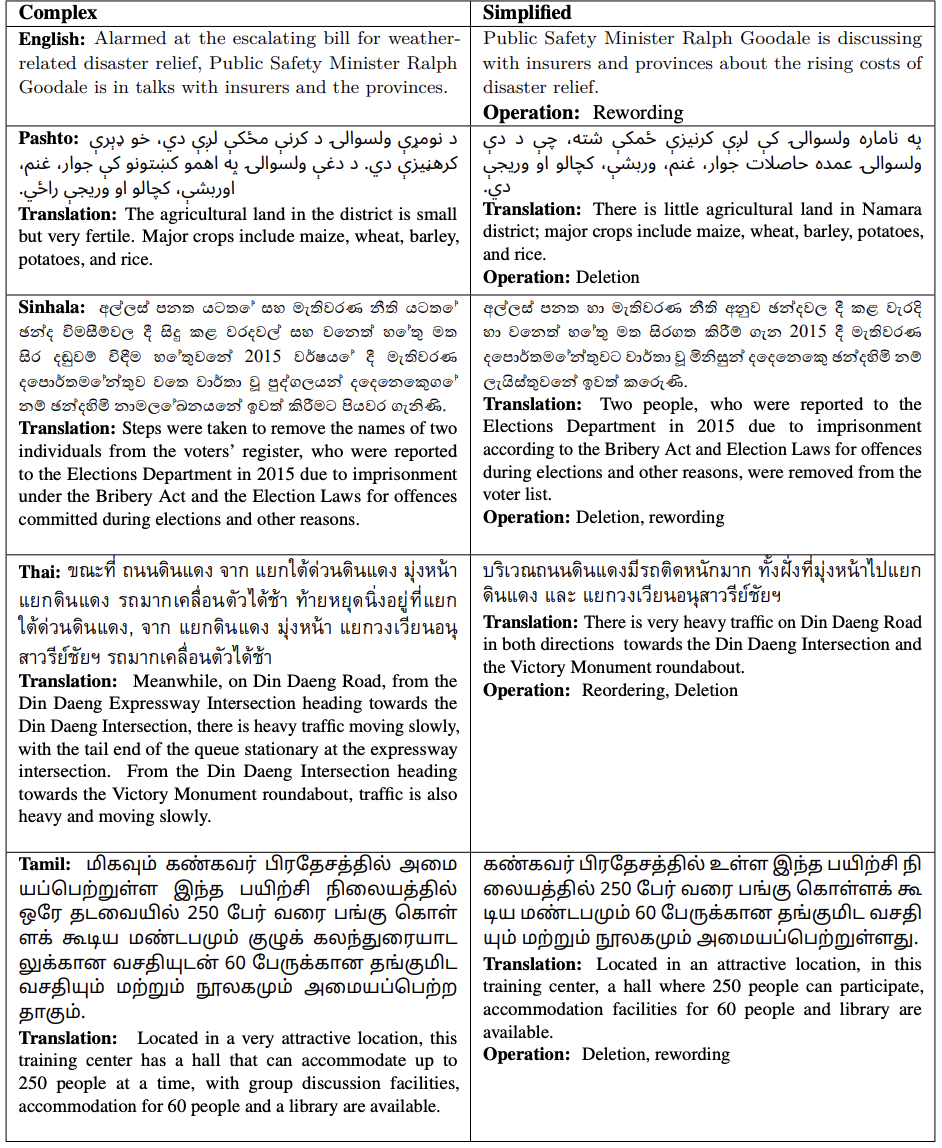
一份政府公告、一页用药说明,公开并不等于读得懂——对第二语言读者、学生和有阅读障碍的人来说,复杂的长句本身就是一道门槛。OasisSimp 为五种语言建立了句子简化的开放评测基准:语料全部由母语者撰写,覆盖英语、僧伽罗语、泰米尔语、泰语和普什图语。
读得到,不等于读得懂
标题里的那次改写,在自然语言处理中称为句子简化(sentence simplification):把一句话改写得更易读,同时不丢失原意。它是公共信息、教育和无障碍阅读的底层能力:政务部门希望公告人人能懂,出版与教育机构需要分级读物,健康信息的可读性更是直接影响理解成本。
英语的句子简化研究有多年积累的基准可用;而对僧伽罗语、普什图语、泰米尔语、泰语这样的低资源语言(可用语料和评测数据稀缺的语言),过去几乎没有任何公开评测——连衡量一个简化系统好坏的尺子都不存在。OasisSimp 补上的正是这把尺子。
母语者写出的评测基准
语料全部来自真实场景:政府文件、新闻与 Wikipedia。9,519 个复杂句中的每一句,都由母语者按统一指南写出多条简化参考(多参考——同一句允许多种可接受的简化写法,避免把某一种答案当成唯一标准)。
数据按 80% test / 20% validation 切分,并以 CC BY 4.0 许可完全开放,定位为评测基准而非训练语料。
| Lang | # Comp Sentences | Avg. Simp Sentences | Avg. Comp Length | Avg. Simp Length | Source Domain |
|---|---|---|---|---|---|
| English | 2500 | 2.86 | 24.35 | 17.23 | News |
| Sinhala | 2500 | 5.00 | 30.12 | 28.78 | Govt |
| Thai | 1499 | 5.06 | 48.24 | 37.77 | News |
| Tamil | 520 | 4.66 | 23.22 | 17.65 | Govt |
| Pashto | 2500 | 3.00 | 28.81 | 20.31 | Wiki |
八个开源模型的现状
论文用 SARI(句子简化的标准自动指标,分别衡量新增、保留、删除三类改写操作,对应表中的 ADD / KEEP / DEL)和 BERTScore(基于语义相似度的自动评分)评测了 8 个开源多语大模型。
结果有两层。少样本示例(few-shot——在提问中附上几个示范例子)几乎在所有语言上带来提升,说明风格可以校准;但低资源语言的绝对表现仍然明显落后,尤其当简化需要新增合适的简单表达,而不只是删掉冗余信息时。
| Model | 0 Shot | 1 Shot | 5 Shot | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SARI Comp. | SARI | Fref | SARI Comp. | SARI | Fref | SARI Comp. | SARI | Fref | |||||||
| ADD | KEEP | DEL | ADD | KEEP | DEL | ADD | KEEP | DEL | |||||||
| Aya ✓ | 9.32 | 44.98 | 75.23 | 43.18 | 54.44 | 9.68 | 44.90 | 72.51 | 42.36 | 56.35 | 10.18 | 45.91 | 71.16 | 42.42 | 57.20 |
| Cmd-R ✓ | 9.69 | 44.95 | 72.89 | 42.51 | 55.90 | 10.99 | 43.71 | 77.57 | 44.09 | 55.03 | 11.91 | 45.28 | 77.09 | 44.76 | 56.63 |
| DeepSeek ✓ | 7.03 | 41.47 | 76.30 | 41.60 | 51.88 | 7.80 | 41.12 | 76.82 | 41.91 | 51.92 | 9.41 | 42.03 | 77.22 | 42.89 | 54.15 |
| EuroLLM ✓ | 9.32 | 45.60 | 68.36 | 41.10 | 56.98 | 10.99 | 46.98 | 69.35 | 42.44 | 57.96 | 11.63 | 46.55 | 70.93 | 43.04 | 58.10 |
| Gemma ✓ | 5.24 | 44.43 | 68.54 | 39.40 | 51.87 | 6.55 | 43.26 | 74.44 | 41.41 | 52.34 | 9.19 | 44.67 | 77.06 | 43.64 | 55.27 |
| LLaMA | 6.48 | 43.31 | 68.34 | 39.38 | 54.30 | 8.11 | 43.42 | 72.83 | 41.45 | 54.53 | 9.93 | 44.75 | 73.75 | 42.81 | 56.00 |
| Mistral ✓ | 8.56 | 43.66 | 77.46 | 43.23 | 52.49 | 10.31 | 43.82 | 78.43 | 44.18 | 54.55 | 11.61 | 44.01 | 78.59 | 44.74 | 55.89 |
| Qwen ✓ | 8.70 | 46.07 | 73.53 | 42.77 | 42.36 | 9.54 | 46.40 | 77.25 | 44.39 | 53.03 | 10.88 | 47.01 | 77.08 | 44.99 | 55.27 |
| Model | 0 Shot | 1 Shot | 5 Shot | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SARI Comp. | SARI | Fref | SARI Comp. | SARI | Fref | SARI Comp. | SARI | Fref | |||||||
| ADD | KEEP | DEL | ADD | KEEP | DEL | ADD | KEEP | DEL | |||||||
| Aya ✕ | 0.62 | 23.98 | 67.47 | 30.69 | 49.17 | 1.08 | 45.60 | 58.62 | 35.10 | 60.83 | 1.77 | 53.81 | 47.17 | 34.25 | 68.25 |
| Cmd-R ✕ | 0.75 | 50.82 | 51.73 | 34.44 | 61.91 | 0.93 | 54.41 | 44.44 | 33.26 | 67.84 | 0.70 | 56.53 | 35.62 | 30.95 | 70.52 |
| DeepSeek ✕ | 0.52 | 41.19 | 60.71 | 34.14 | 38.65 | 0.90 | 48.83 | 54.59 | 34.78 | 63.65 | 0.91 | 50.16 | 52.51 | 34.53 | 66.26 |
| EuroLLM ✕ | 0.50 | 54.28 | 44.40 | 33.06 | 67.55 | 0.65 | 54.87 | 43.28 | 32.93 | 69.72 | 0.78 | 55.37 | 42.09 | 32.75 | 70.42 |
| Gemma ✕ | 3.84 | 25.08 | 70.78 | 33.23 | 56.95 | 4.47 | 34.75 | 68.57 | 35.93 | 61.47 | 5.39 | 46.39 | 61.95 | 37.91 | 66.04 |
| LLaMA ✕ | 0.70 | 18.34 | 70.28 | 29.77 | -22.40 | 3.15 | 46.28 | 61.67 | 37.04 | 51.15 | 1.96 | 46.53 | 58.15 | 35.55 | 33.03 |
| Mistral ✕ | 0.94 | 26.36 | 68.13 | 31.81 | 47.73 | 1.42 | 41.20 | 63.04 | 35.22 | 61.31 | 1.51 | 45.93 | 58.60 | 35.35 | 64.40 |
| Qwen ✕ | 2.34 | 47.48 | 58.92 | 36.25 | 58.02 | 2.81 | 49.88 | 55.34 | 36.01 | 64.76 | 2.62 | 53.79 | 48.71 | 35.04 | 65.57 |
- 多参考很关键。单一简化目标会低估可接受改写空间。
- 少样本有效但不够。示例能校准风格,却不能消除语言资源差距。
- ADD 最难。模型擅长删除冗余信息,但在低资源语言中很难新增合适的简单表达。