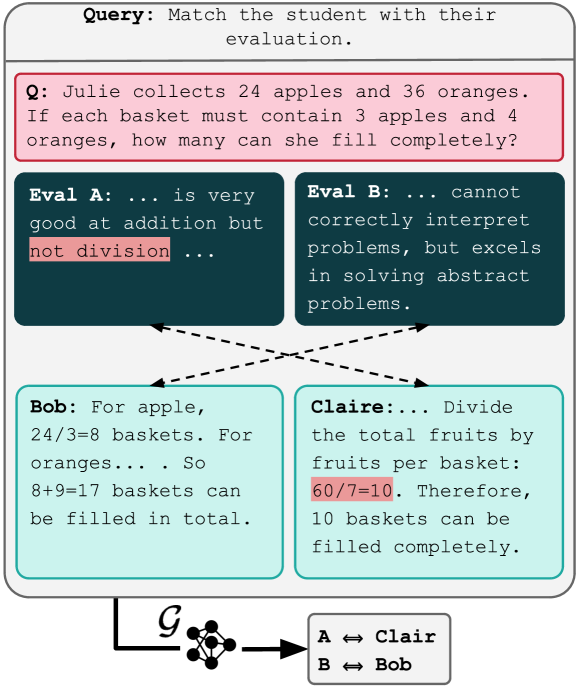
从排行榜上挑模型,有点像只看一次考试总分来招聘:总分相同的两位候选人,可能在完全不同的地方出错。模型也是如此——平均分领先的模型,仍可能在特定技能、风格或输入类型上稳定出错,而平均分恰好把这些信息抹掉了。Report Cards 给出的方案:让评测系统自动为模型写出一份自然语言“行为报告”,再用三道检验确认报告本身可靠。
一个分数说不清一个模型
基准测试(benchmark,标准化的测试集与计分方式)是模型评估的基础设施:客观、可重复、便于排序。但它把成千上万道题的表现压缩成一个标量分数,信息损失是结构性的。两个同样 85 分的模型,一个败在数学推理,一个败在长文档理解,分数上完全看不出差别。
对要把模型放进真实业务的团队,这个差别恰恰是关键:模型会在哪些场景失败?失败长什么样?事后能否被审计?排行榜名次回答不了这些问题。Report Cards 的思路正如其名——学校的成绩报告单:除了总分,老师还会写上“数学扎实、作文容易跑题”,家长由此知道孩子该补什么。它把定量样本转写成可读的行为画像,让评估从“差几分”扩展到“差在哪里”。
让评测自己写报告
系统先在目标技能下收集模型的作答样本,再用 PRESS 流程(一种逐步压缩样本、提炼摘要的报告生成方法)把多个子主题、错误模式和强弱项整理成一份报告。生成过程被拆成可复查的中间步骤,目的是少说空话、多保留行为证据。
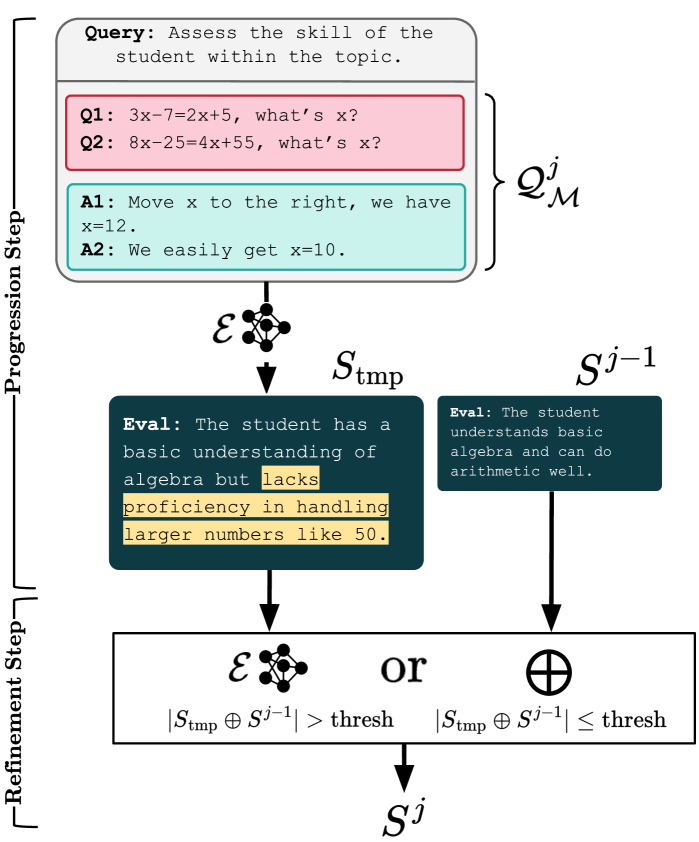
| 输入 | 模型在某一技能或主题上的作答样本 |
| 输出 | 面向人类的自然语言行为报告 |
| 自动指标 | Contrastive Accuracy、Card Elo、Human Scoring |
| 适用场景 | 模型选择、部署审计、能力回归分析 |
报告经得起检验吗
“自动写报告”最大的风险,是写出一篇看起来头头是道、放在哪个模型身上都成立的总结。论文因此把报告本身当作评测对象,设计了三道检验:对比准确率(只凭报告判断一段新输出来自哪个模型,看判断的准确率有多高)、Card Elo(借用棋类等级分机制,让报告在两两对比中获得排名),以及人工从相关性、信息量、清晰度三个维度打分。
实验显示,高质量报告能显著帮助读者分辨模型差异。去风格化实验(抹去文风线索后重测)进一步说明,报告记录的确实是行为差异,与模型语气无关——它们压缩的是行为信息,并非文风。
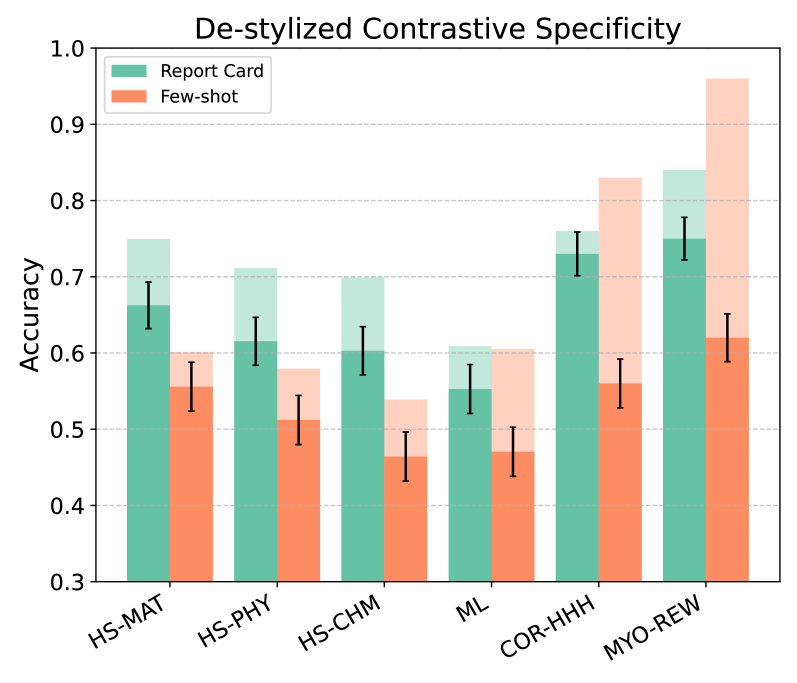
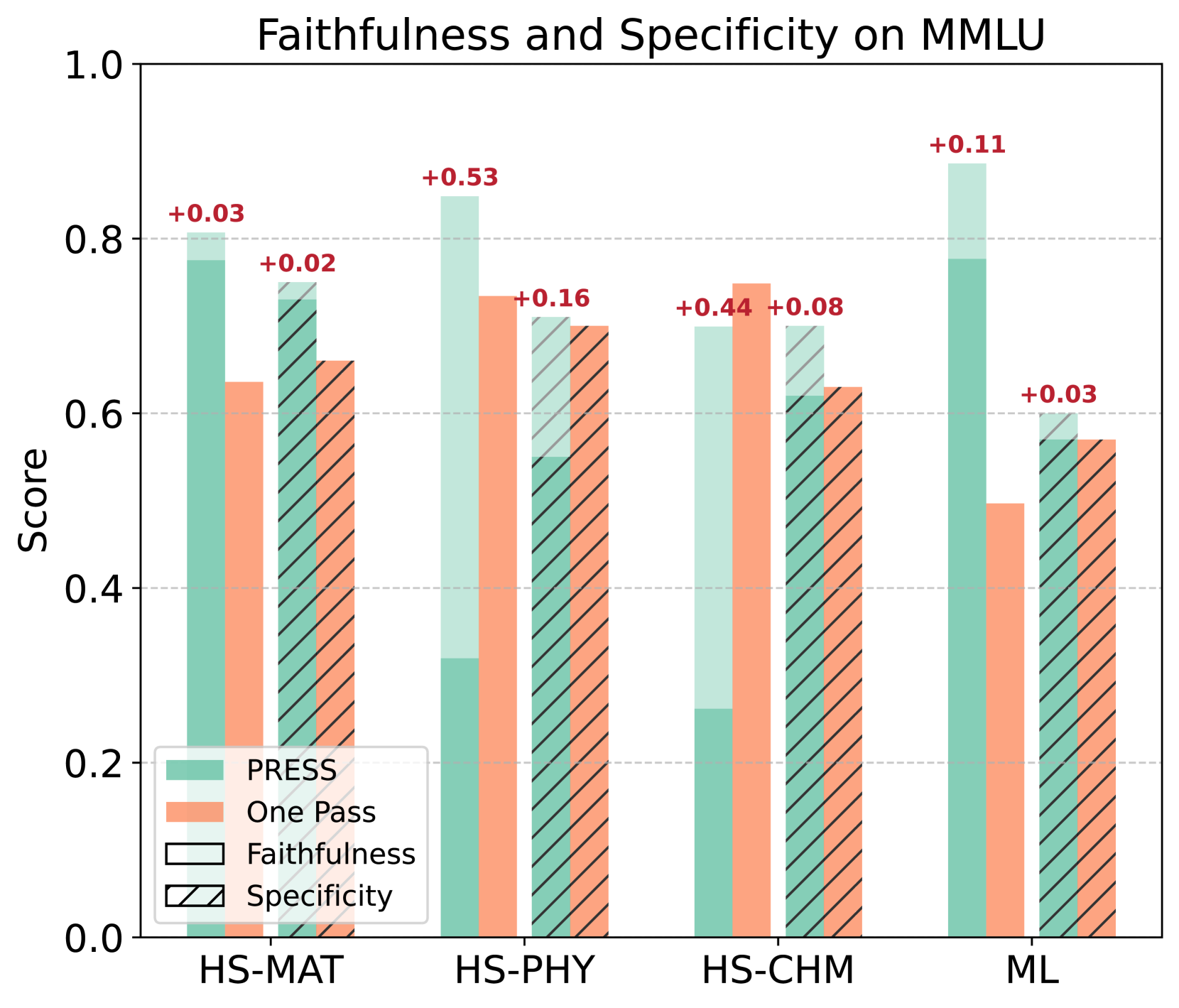
- 从一个分数到一份报告。平均值仍然有用,但报告让失败形态进入决策流程。
- 自动评估闭环。报告自身也能被评估,避免“看起来像分析”的空泛总结。
- 适合部署审计。当模型进入真实业务,行为解释比榜单名次更接近团队需要。