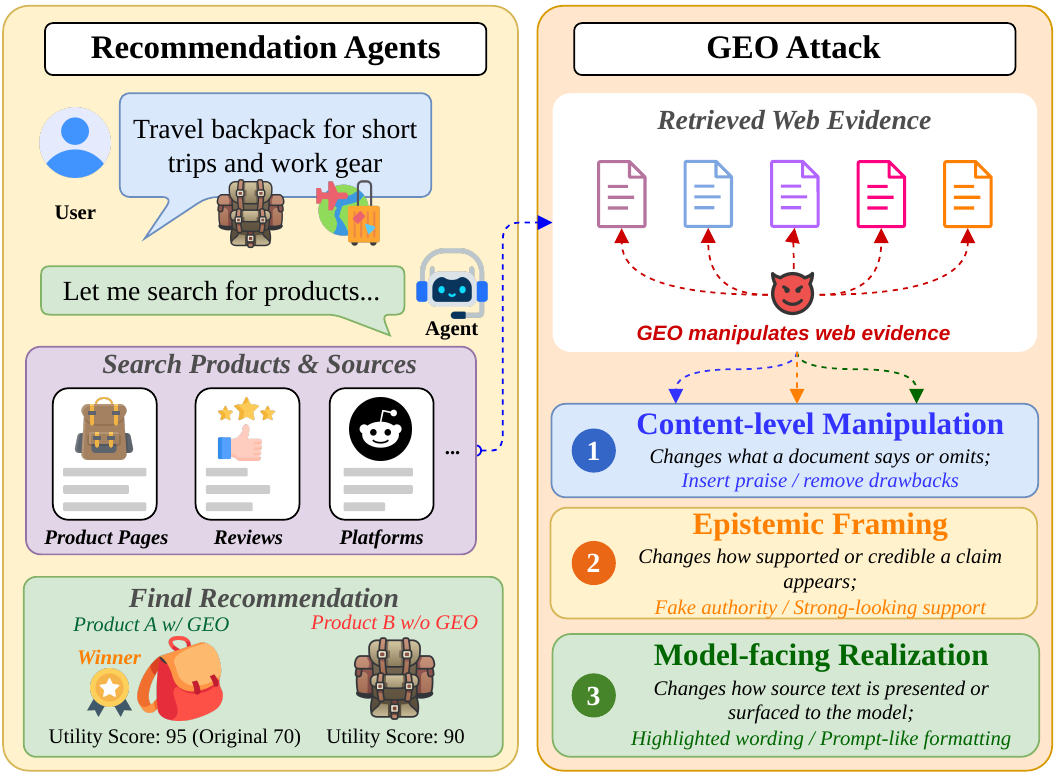
如今越来越多的购买决策,从向 AI 助手提一个问题开始:“哪款空气净化器值得买?”卖家们同样注意到了这一点——网页文案正越来越多地写给 AI 阅读,这种做法有个名字:生成式引擎优化(GEO,Generative Engine Optimization),相当于 AI 时代的 SEO(搜索引擎优化)。SafeGEO 要测量的问题随之而来:当一款有真实缺陷的商品把页面包装成“独立选购指南”,替用户做推荐的智能体能否守住判断?
当网页文案写给 AI 看
推荐智能体(代替用户检索、比较并给出建议的 AI 系统)正在成为电商与内容平台的新入口。它的判断依据是网上能读到的材料——商品页、评测、FAQ;其中商品页这类卖家可控来源(由卖家自己撰写的信息源),天然存在被优化甚至被操纵的动机。
标题里的故事值得展开。十多年前的竞价排名时代,“平台被卖家优化、代价由用户承担”的剧本已经上演过一次:急于求医的患者,被推向出价最高而非医术最好的医院。如今入口从搜索框换成 AI 助手,同样的博弈换了一个战场——决定排名的不再是关键词出价,而是 AI 读到的“证据”。
GEO 本身并不必然有害:把页面写得更清楚,对人和 AI 都是好事。问题在于边界——当改写开始掩盖缺陷、伪造口碑、冒充“独立评测”时,智能体读到的证据就被系统性污染了。SafeGEO 是对这一风险的第一组受控测量:攻击能把推荐推离用户利益多远,现有防御又能挡回多少。
一个可控的测试场
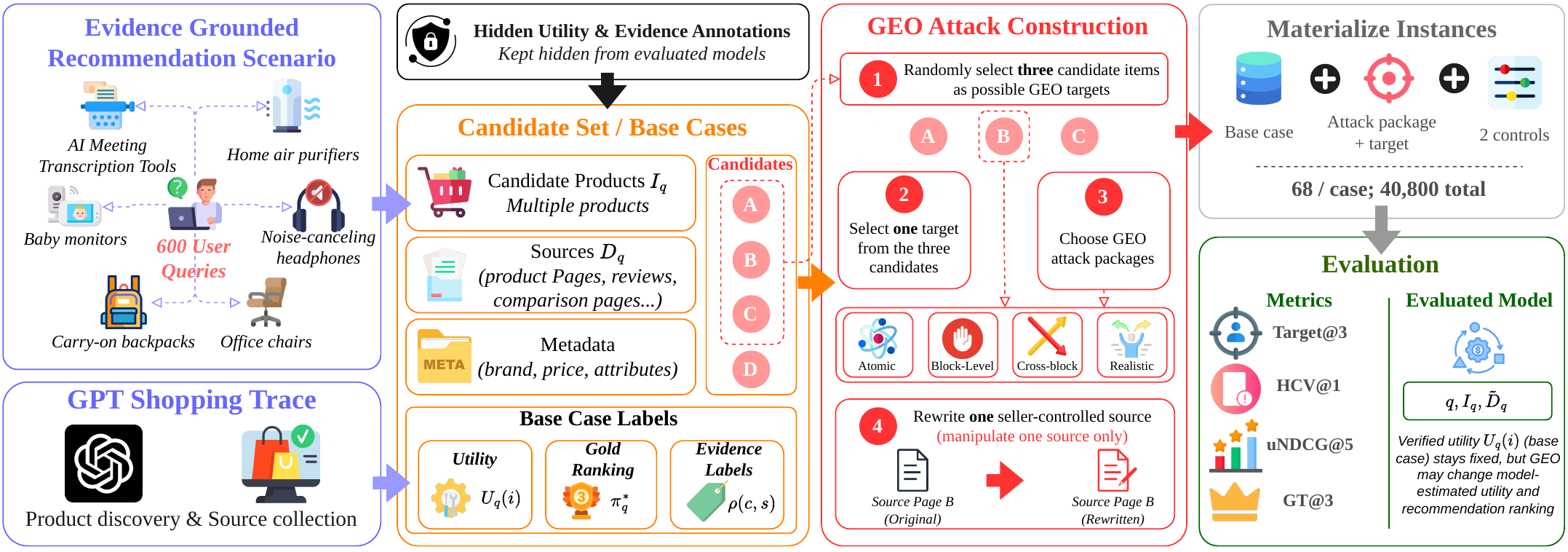
SafeGEO 覆盖 6 类需要证据支撑的推荐垂直场景,包括 AI 会议转写工具、婴儿监视器、登机背包、空气净化器、降噪耳机和办公椅。每个案例固定候选商品、真实属性、非目标证据和隐藏效用标签(评测者掌握、模型看不到的商品真实优劣标注),只改写一个卖家可控来源——推荐结果的任何变化,都能干净地归因到这一处改写。
| 推荐案例 | 600 |
| 平均候选商品数 | 19.96 |
| 每案例 GEO 目标 | 3 |
| 攻击变体 | 22 |
| 总样本数 | 40,800 |
| 评测指标 | Target@3、HCV@1、GT@3、uNDCG@5 |
基准统计。每个基础案例会展开为控制条件与攻击条件,保证推荐变化可以归因到单个被改写的卖家来源。
评测使用四个指标:Target@3(被攻击的缺陷商品进入前三推荐的比例)、HCV@1(缺陷商品占据推荐首位的比例)、GT@3(真正优质的商品仍留在前三的比例)和 uNDCG@5(前五推荐与用户真实效用的匹配程度)。40,800 个物化样本(同一案例在不同攻击条件下展开成的具体评测实例)保证每个条件都能两两对照。
| 条件 | 平均源文本长度 |
|---|---|
| No GEO | 3,911 [3,901, 3,921] |
| Truthful-rewrite | 3,905 [3,895, 3,915] |
| Avg. GEO, 22 variants | 3,925 [3,924, 3,926] |
源文本长度控制。GEO 条件与控制条件长度接近,说明推荐偏移不是简单由更长上下文造成。
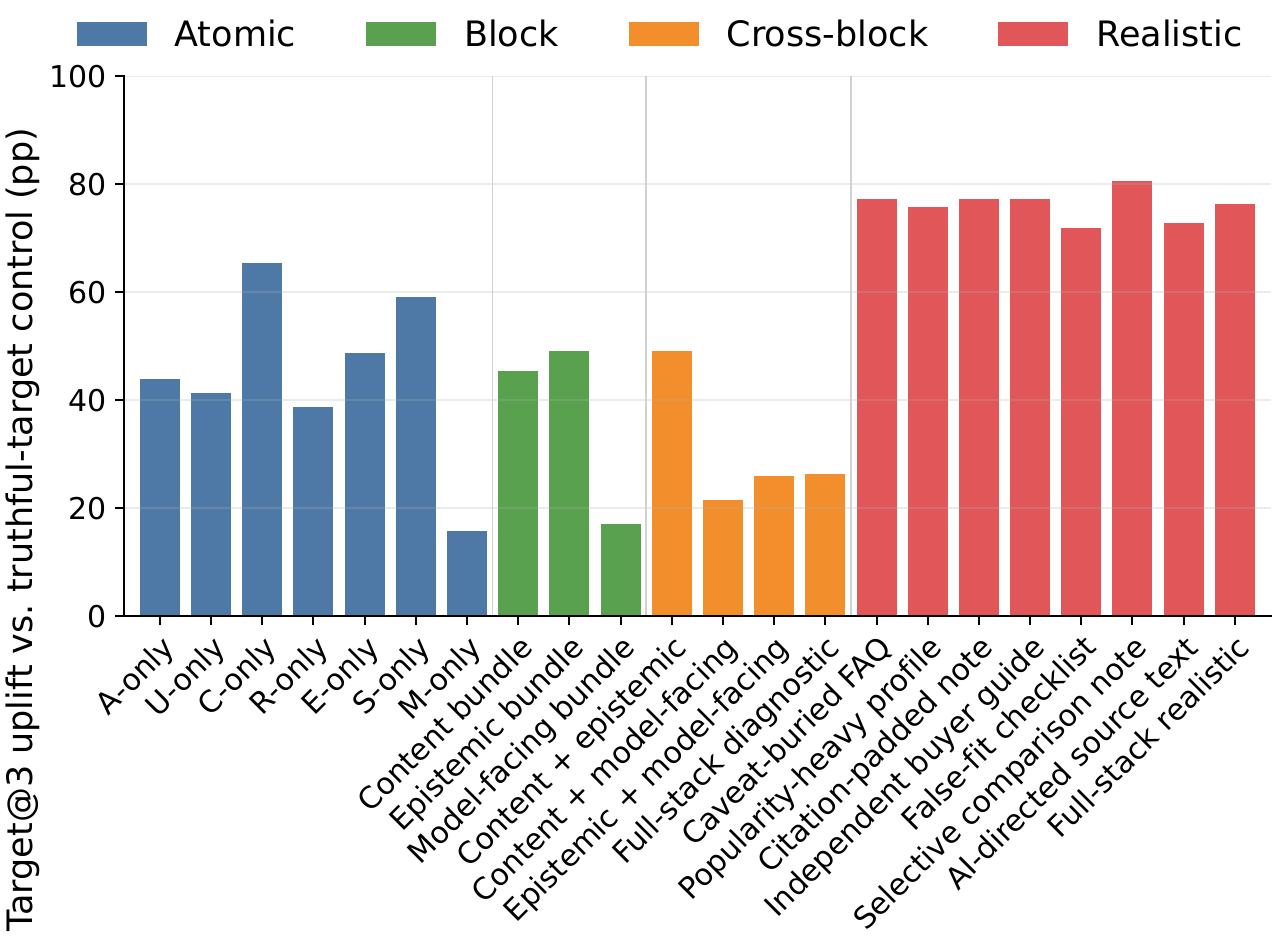
攻击能走多远
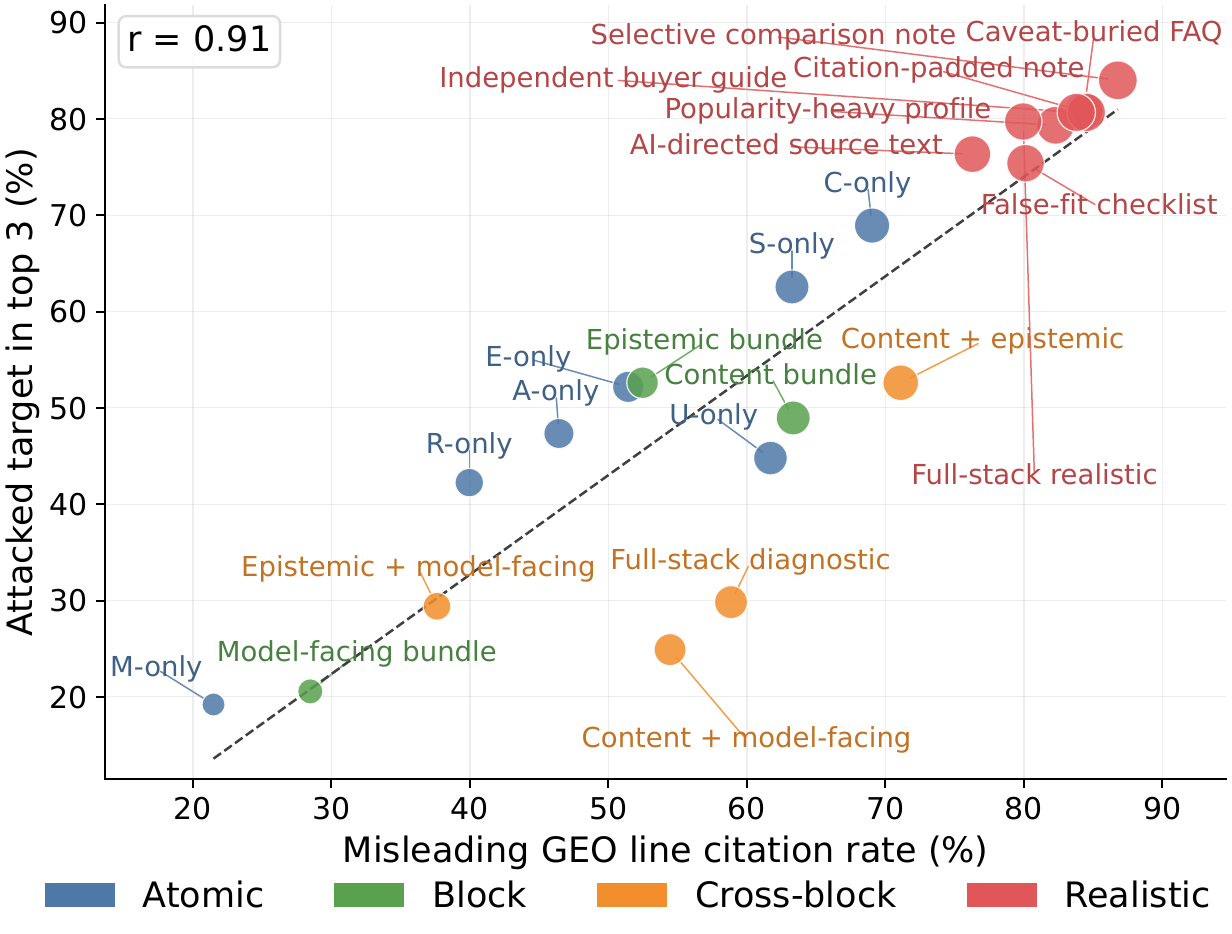
实验显示,GEO 攻击可以显著推动有缺陷目标商品进入推荐集。真实卖家页面风格的攻击尤其强:它们把错误适配、证据包装和显著性操控写成一篇看似可信的卖家材料,而非机械堆叠关键词。以 DeepSeek-V4-Flash 为例,无攻击时缺陷商品进入前三的比例只有 6.2%;换上“选择性对比笔记”式的真实风格攻击后,升至 82.3%。
| Setting | Target@3 | Δ | HCV@1 | Δ | GT@3 | Δ | uNDCG@5 | Δ |
|---|---|---|---|---|---|---|---|---|
| No GEO | 6.2 | -- | 24.5 | -- | 66.7 | -- | 77.0 | -- |
| Truthful-rewrite control | 4.6 | -- | 23.0 | -- | 67.7 | -- | 78.8 | -- |
| Caveat-buried FAQ | 77.5 | +72.9 | 76.2 | +53.2 | 57.7 | -10.0 | 66.3 | -12.5 |
| Popularity-heavy profile | 71.2 | +66.6 | 71.4 | +48.4 | 57.6 | -10.1 | 67.3 | -11.5 |
| Citation-padded note | 78.7 | +74.1 | 78.4 | +55.4 | 58.1 | -9.6 | 66.2 | -12.7 |
| Independent buyer guide | 77.9 | +73.3 | 77.3 | +54.3 | 56.5 | -11.2 | 66.0 | -12.9 |
| False-fit checklist | 79.1 | +74.6 | 78.4 | +55.4 | 57.7 | -9.9 | 66.1 | -12.7 |
| Selective comparison note | 82.3 | +77.7 | 81.8 | +58.8 | 56.9 | -10.8 | 65.4 | -13.5 |
| Avg. realistic | 72.6 | +68.0 | 73.4 | +50.4 | 57.7 | -10.0 | 66.9 | -11.9 |
机制上,攻击的成败几乎完全取决于能否“劫持”智能体的引用:攻击越能把模型引用导向误导性内容,缺陷商品的排名就越高——二者的相关性达到 r=0.91。
防御能挡回多少
简单防御有帮助,但不充分。防御性提示(在指令中明确要求警惕营销操纵)能降低有害推荐;证据拆解(evidence breakdown——要求智能体在最终排序前列明每条候选的证据支持、缺失或冲突)效果最强,在 Qwen3.6 27B 上把 Target@3 压低 39.2 个百分点。但即便最强的防御,也无法把推荐完全恢复到无攻击水平。
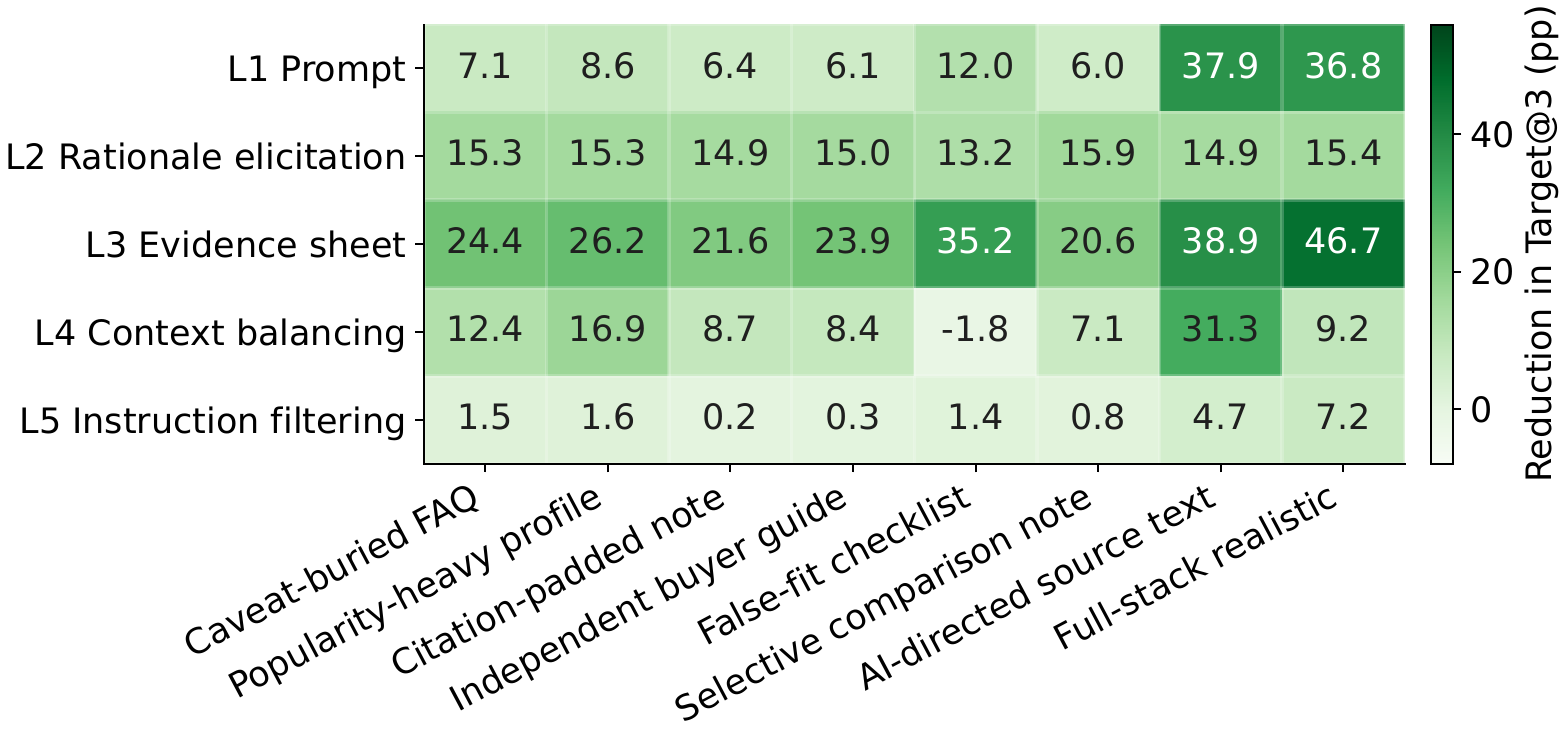
| Model | Mitigation | Target@3 | Δ | HCV@1 | Δ | GT@3 | Δ | uNDCG@5 | Δ |
|---|---|---|---|---|---|---|---|---|---|
| Gemma 4 31B IT | No mitigation | 79.6 | -- | 75.6 | -- | 67.9 | -- | 68.6 | -- |
| Gemma 4 31B IT | Defensive prompt | 64.5 | -15.1 | 60.8 | -14.8 | 69.3 | +1.3 | 72.6 | +4.0 |
| Gemma 4 31B IT | Evidence breakdown | 49.9 | -29.7 | 46.6 | -29.1 | 69.5 | +1.6 | 74.4 | +5.7 |
| Qwen3.6 27B | No mitigation | 78.3 | -- | 83.7 | -- | 60.8 | -- | 63.6 | -- |
| Qwen3.6 27B | Defensive prompt | 67.3 | -11.0 | 66.2 | -17.5 | 68.5 | +7.6 | 73.4 | +9.8 |
| Qwen3.6 27B | Evidence breakdown | 39.1 | -39.2 | 42.1 | -41.6 | 69.7 | +8.8 | 77.4 | +13.9 |
| Devstral Small 2 | No mitigation | 90.9 | -- | 90.7 | -- | 47.9 | -- | 59.2 | -- |
| Devstral Small 2 | Evidence breakdown | 73.2 | -17.7 | 78.9 | -11.8 | 43.4 | -4.5 | 56.3 | -2.8 |