同一个棋局,可以画成棋盘,也可以写成一行记谱;同一个分子,可以画成结构图,也可以写成一串字符。信息完全相同,只是形式不同。我们默认“既能看图又能读文字”的 AI 模型在两种形式下会给出同一个答案——SEAM 的测量显示,目前远非如此。
换一种形式,答案就变了
能同时处理图像与文字的大模型,统称视觉语言模型(VLM)。它们在演示中读图表、答文档,表现常常令人印象深刻。但要把判断托付给这样的系统,有一个更基础的要求:同一份信息,无论以图片还是文字呈现,结论应当一致。答案会随文件格式改变的助手,无法让人放心使用。
过去的多模态测试大多把文字截图进图片里,属于 OCR 式测试(OCR:从图片中识别文字),分不清模型究竟是“看不懂图”还是“读不懂题”。SEAM 把“同一语义、不同模态”做成可控实验:每道题都有文字版、图像版和图文并排版,模型在三种条件下分别作答,结果互相对照。
四个领域的等价表示
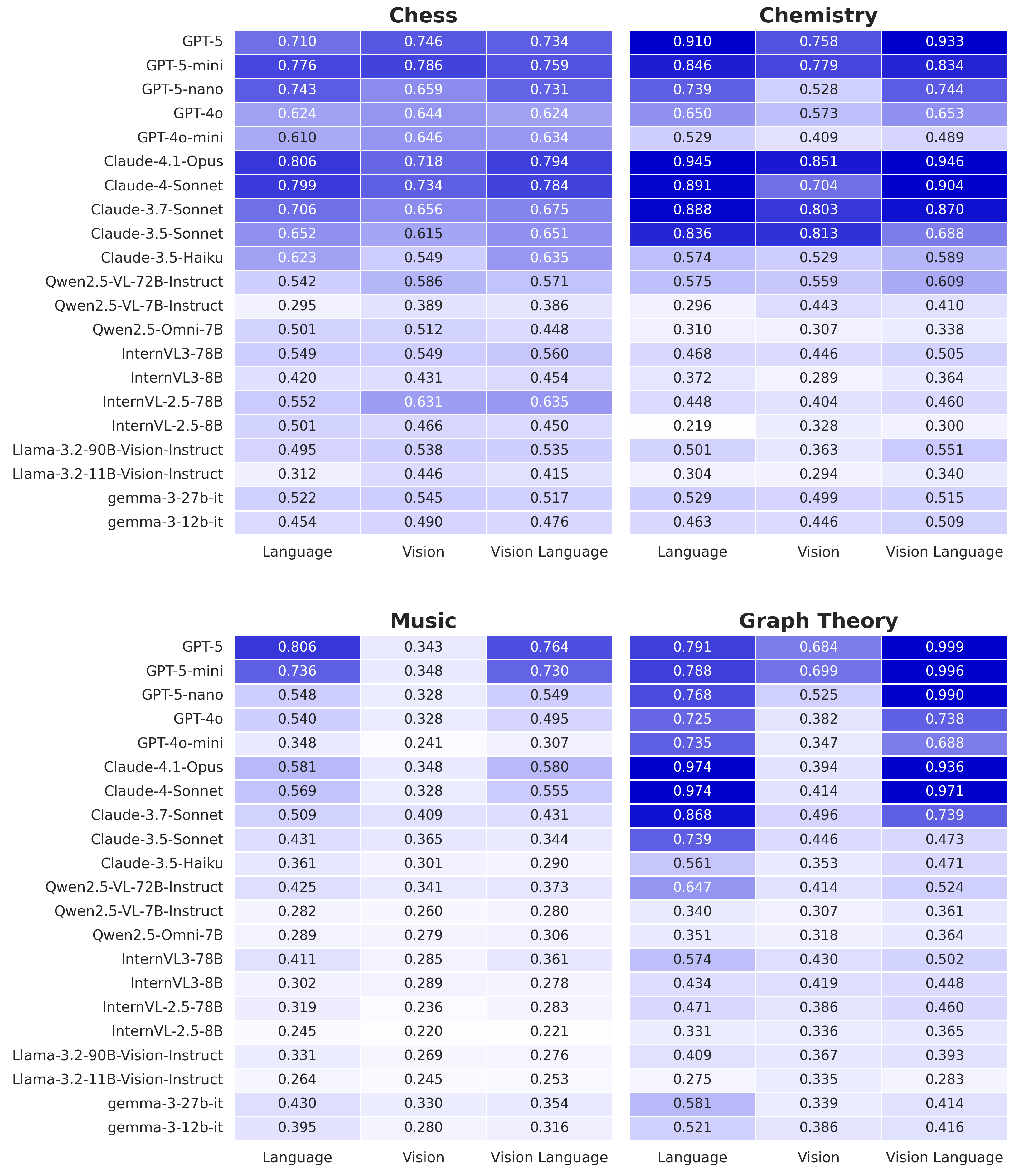
可控的关键在于“等价”。SEAM 选择了四个天然拥有成熟文字记法与视觉表示的领域:国际象棋有 FEN(用一行字符完整记录棋盘局面的标准记法)与棋盘图,化学有 SMILES(用字符串描述分子结构的化学记法)与分子图,音乐有 ABC 记谱(用字母符号记录乐谱的文本格式)与五线谱,图论有邻接矩阵(用表格记录节点连接关系)与节点边图。文字和图像各自是该领域的原生表示,承载的信息严格相同。
如此构造出的成绩差异,只能来自模型对不同表示形式的处理,而与任务难度无关。
| 领域 | Chess · Chemistry · Music · Graph theory |
| 任务 | 16 个任务,每个领域 4 个 |
| 条目 | 3,200 道基础题;语言、视觉、图文三种条件共 9,600 次评测 |
| 模型 | 21 个前沿 VLM,覆盖闭源与开源系统 |
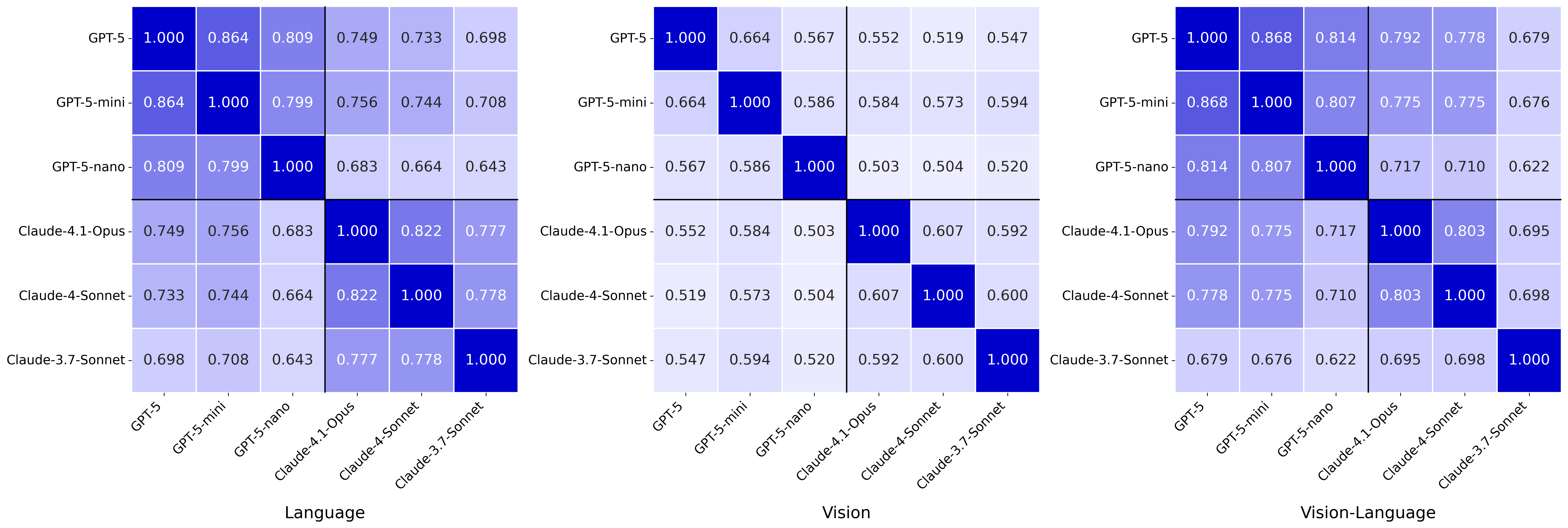
21 个模型的一致性测量
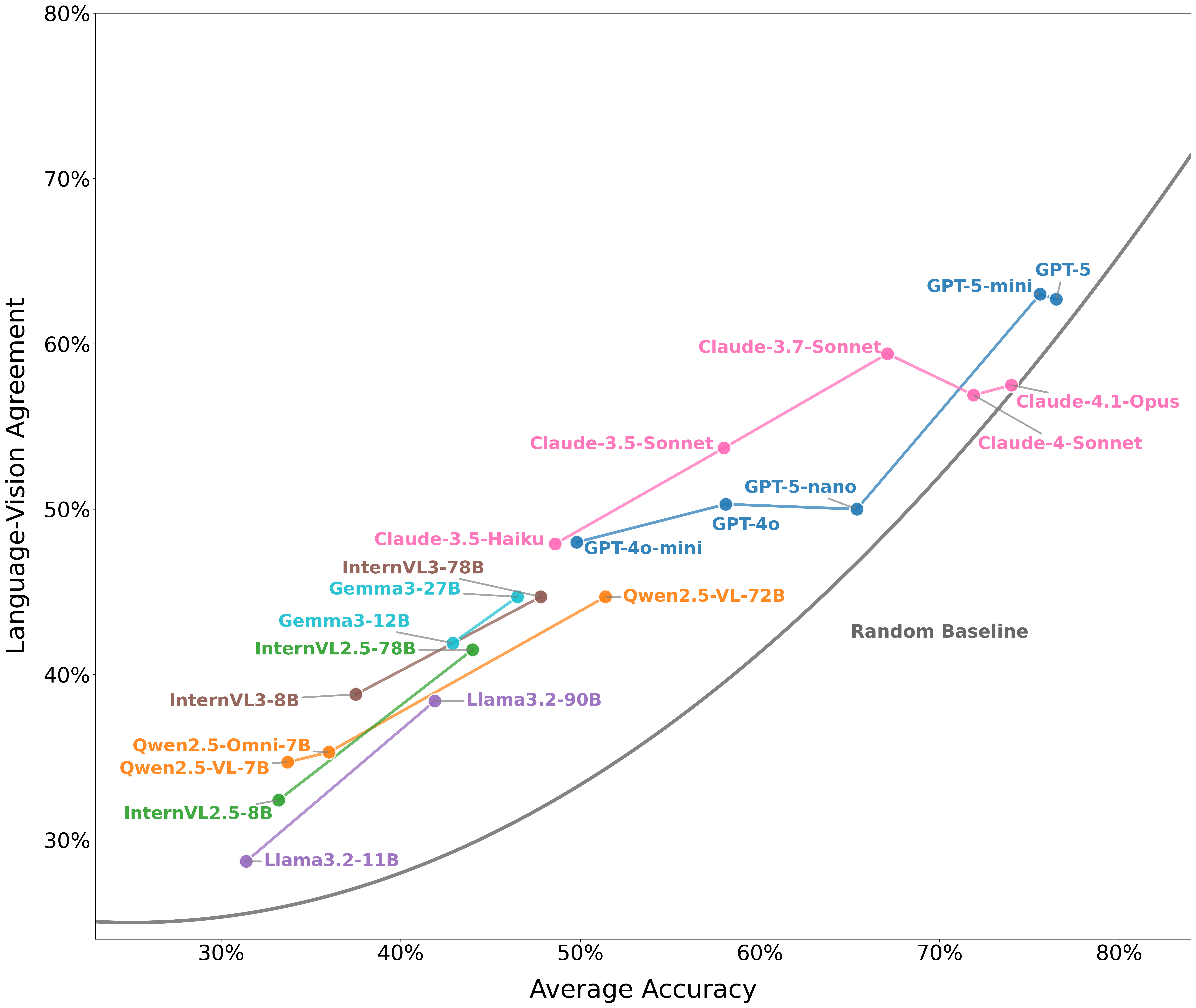
全部 9,600 次评测覆盖 21 个前沿 VLM,包括闭源与开源系统。总体规律清晰:模型在文字侧通常更强,视觉侧明显更弱;更值得注意的是,同一个模型对同一道题的文字版和图像版,经常给出不同答案。这说明系统尚未学到稳定的跨表示推理。
- 视觉常常落后于语言。即便信息等价,视觉通道仍更容易掉分。
- 一致性不会自动出现。同一题换一种表示,答案就可能改变。
- 错误可诊断。文字侧常见符号解析失败;视觉侧常见结构幻觉——模型“看到”图中并不存在的棋子、化学键或连线。
给多模态评测的新坐标
给“模态无关推理”一个干净坐标。SEAM 让研究者能看清模型到底是看不懂、读不懂,还是不能把两种表示映射到同一语义。
适合作为 VLM 回归测试。新模型如果只提升平均分但不提升一致性,仍然不能说自己真正更稳。
从展示能力转向诊断能力。比起更多能力演示,多模态系统更需要能定位失败源头的基准。