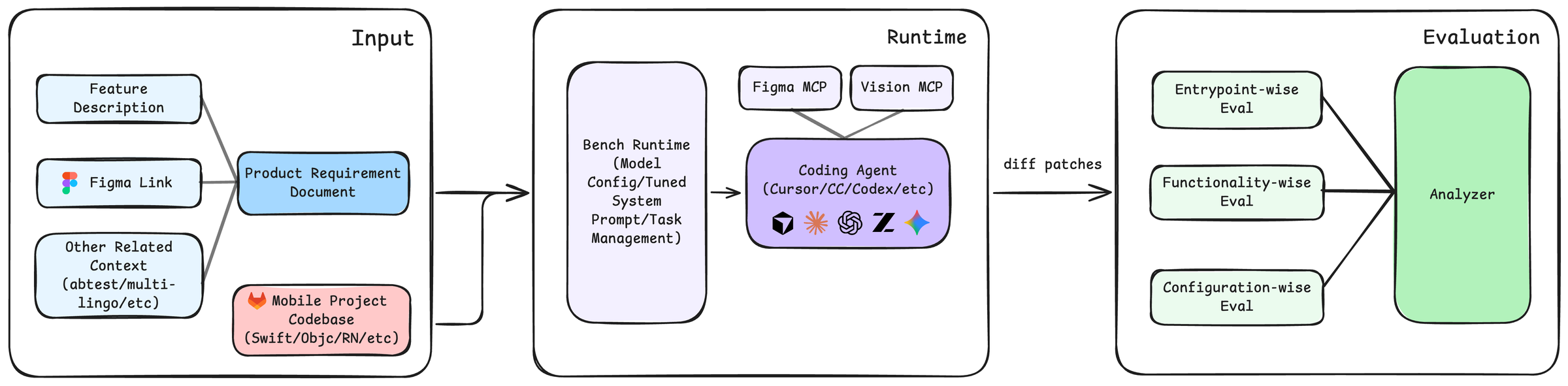
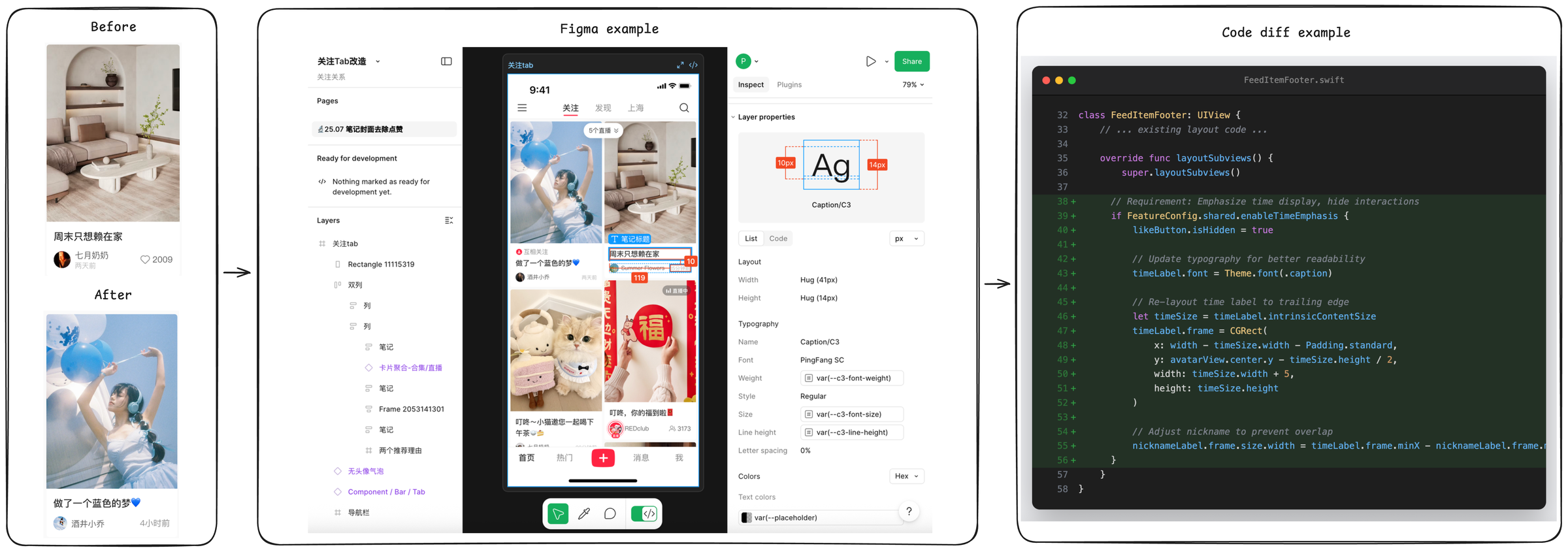
SWE-Bench Mobile 把"智能体写代码"的评测从开源 GitHub 仓库搬进了一款真实在线的移动产品。50 个工程任务全部来自小红书生产 iOS 应用,每个任务配上原始 PRD、Figma 设计稿与人工写的测试套件,让智能体像真正的 iOS 工程师那样读多模态规格、改一个约 50 万行的 Swift / Objective-C 混合代码库。
结果给出了清晰的能力边界:即便是商业上最强的智能体 + 模型组合,也只能解决 12% 的任务。而且——选哪个智能体和选哪个模型同等重要:同一个模型换个脚手架(scaffold——驱动模型读码、改码、跑测试的智能体框架),通过率能差出 6 倍。好比同一位大厨换一间厨房,出品也会大不相同——灶台与流程的影响,和厨艺本身一样真实。论文已正式收录于 KDD 2026 应用数据科学方向(主会,CCF-A 顶会)。
为什么需要它
既往的智能体编程基准在四个维度上都"低估"了真实工程:开源仓库可能被预训练污染;任务多是修 bug 而非加功能;规格是 GitHub issue 而不是设计文档;测试通常已经存在。SWE-Bench Mobile 把这四点全部反过来——代码库是一款真实的生产 iOS 应用,任务是带 PRD 和 Figma 的功能新增,评测平台只在线运行,测试集不公开下载,从机制上降低数据污染风险。
基准构成
| 来源 | 小红书生产 iOS 应用 |
| 编程语言 | Swift + Objective-C(混合) |
| 任务数 | 50 |
| 测试用例 | 449(约每任务 9 条) |
| 代码规模 | 约 50 万行 |
| 每任务输入 | PRD + Figma 设计 + 代码库快照(多模态) |
| 输出 | 统一 diff |
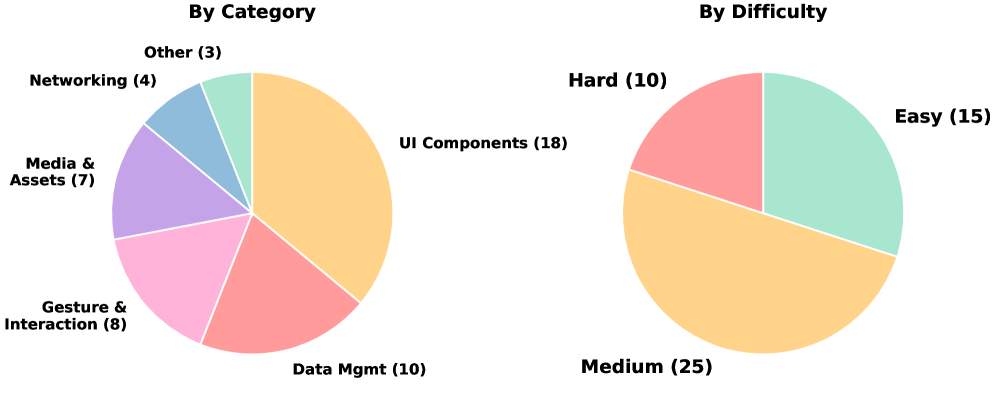
| 视觉素材 | 35 个任务包含 Figma 设计,46 个任务包含参考图 |
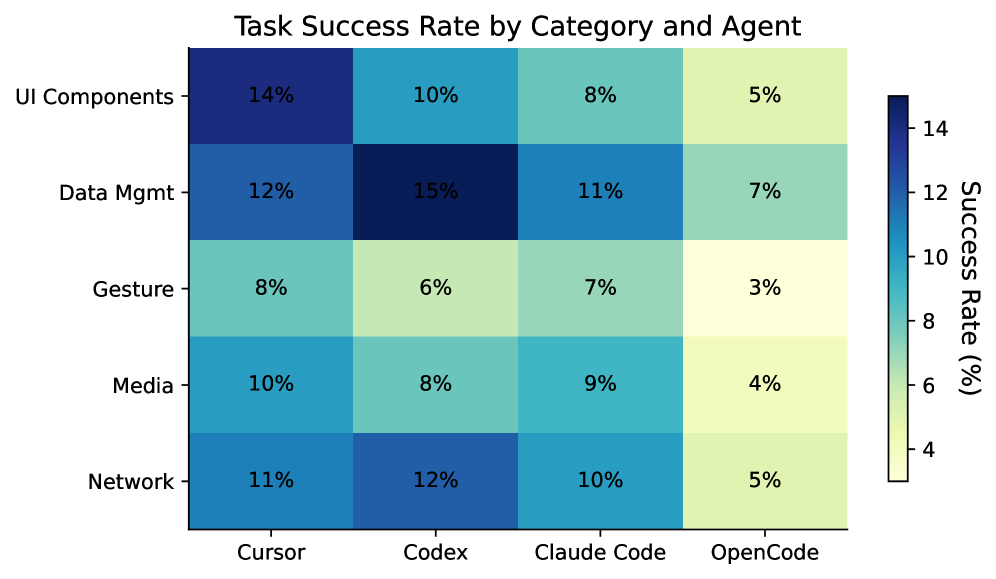
| 任务分布 | UI 组件 18 · 数据管理 10 · 手势交互 8 · 媒体资源 7 · 网络 4 · 其他 3 |
| 任务类型 | 功能新增(非修 bug) |
| 评测方式 | 仅线上托管(防污染) |
基准组成。"任务类型"是与既往智能体基准最大的差别:功能新增逼着智能体去构建,而不只是修。
主要结果
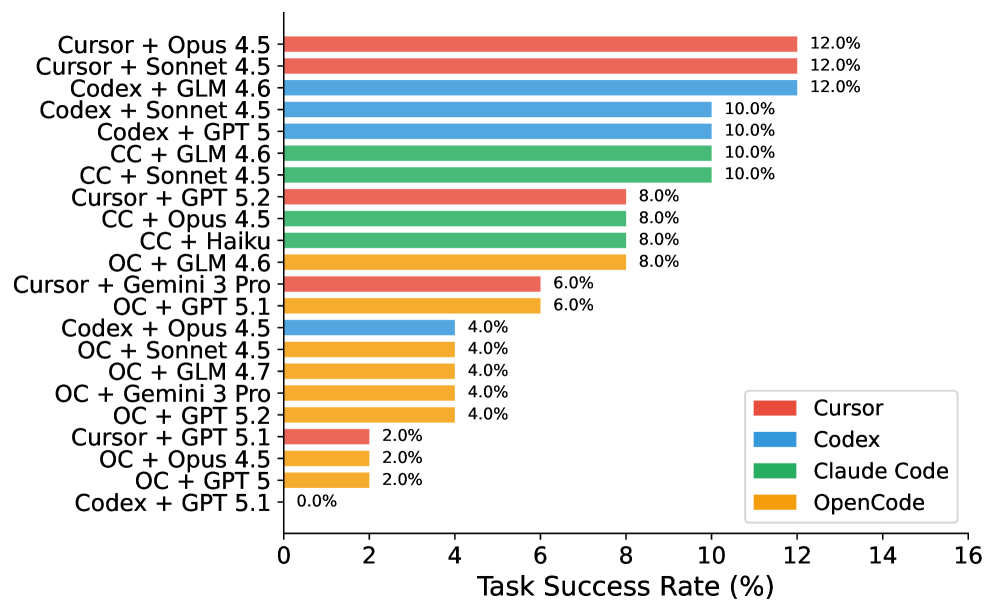
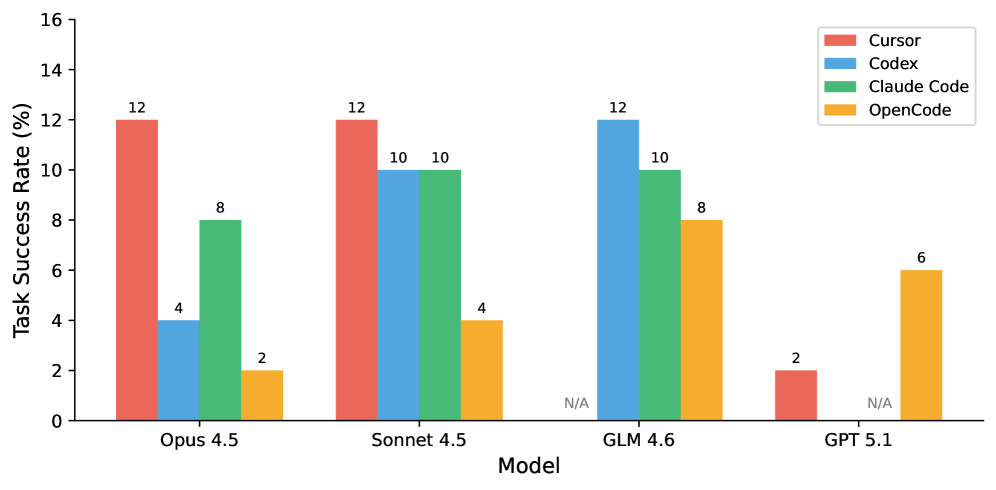
我们评测了 22 种智能体–模型组合,覆盖 4 个智能体(Cursor、Codex、Claude Code、OpenCode)与若干领先的商业及开源模型。排行榜头部如下:
| 智能体 + 模型 | 任务通过 | 测试通过 |
|---|---|---|
| Cursor + Claude Opus 4.5 | 12.0% | 28.1% |
| Cursor + Claude Sonnet 4.5 | 12.0% | 26.7% |
| Codex + GLM 4.6 | 12.0% | 19.6% |
SWE-Bench Mobile 排行榜头部。前三名"任务通过率"并列 12%,但"测试通过率"差出 8.5 个百分点——这是粗粒度通过 vs 细粒度能力的差距。最新结果见 swebenchmobile.com。
关键发现
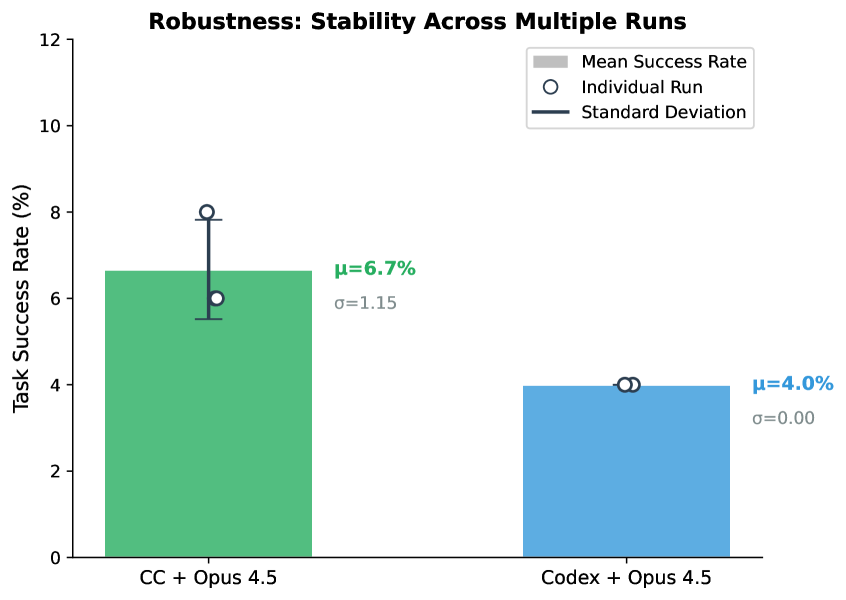
- 同一个模型,不同智能体——最大差出 6 倍。"脚手架"在重要性上几乎与模型本身相当。
- 简单提示赢过复杂提示。一句"防御式编程"提示比更精巧的提示策略多 7.4 个百分点。
- "测试通过率"这一栏值得看。表面上"失败"的任务往往通过了相当一部分测试——只看 pass@1 就会丢掉这部分信号。
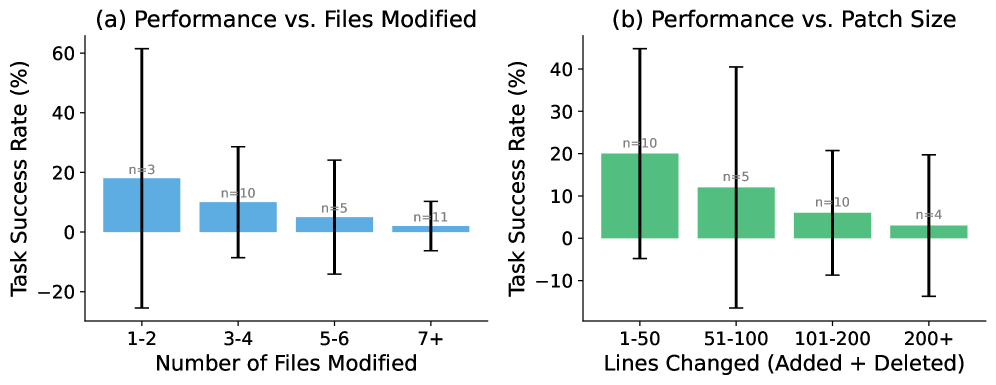
- 复杂工程仍是短板。需要跨 7 个以上文件的任务成功率仅 2%,小补丁任务明显更容易通过。
- 生产部署知识会卡住智能体。常见失败包括遗漏 feature flag、数据模型、关键文件、UI 组件和必要方法。
同一个模型在不同智能体里能差出 6 倍。只报告 LLM 名称的评测,丢掉了一半故事。
意义
给行业的信号
SWE-Bench Mobile 的结论并不悲观。12% 的严格任务通过率说明,当前智能体距离"独立客户端工程师"还有明显距离;但最高 28.1% 的测试通过率也说明,它们已经能在真实工程里干出一部分活。更准确的定位是:AI 编程智能体正在成为有用的 Copilot,还不是可以无人监督接管复杂移动端迭代的 Auto Developer。
参与评测
托管挑战、公共排行榜,现在就开放提交。把你的"智能体 + 模型"放上去,跟所有人在同一套真实生产 iOS 任务上正面比一次。论文已收录于 KDD 2026 主会(CCF-A)。