模型答错了,你提醒它“再检查一遍”,它却常常原样重复,甚至把对的改错。ThinkTwice 要回答的问题由此而来:如果“再看一眼”是一种能力,能否直接把它训练出来?实验给出了肯定的回答:不需要任何额外的监督信号,训练开销只多约 3%,竞赛数学题成绩提升 11.5 个百分点。

“再检查一遍”为什么常常落空
当前让大模型学会推理的主流训练方式叫 RLVR(可验证奖励强化学习——只按最终答案的对错给分):让模型解大量数学题、写大量代码,答对得分,答错不得分。这种训练把模型的“第一次作答”磨得越来越强,竞赛级数学题的成绩因此快速上涨。
但在整个训练过程中,模型从未练习过“复查自己”这个动作。它见过海量题目的第一遍解法,却几乎没有见过“拿到一份自己的答案,再把它改对”的过程。这像极了一个只刷题、从不检查卷子的学生:考场上老师提醒他“回头检查一遍”,他多半也只是把原答案重抄一遍。于是出现了开头的一幕:被要求复查时,模型要么照抄原答案,要么没有方向地重写。
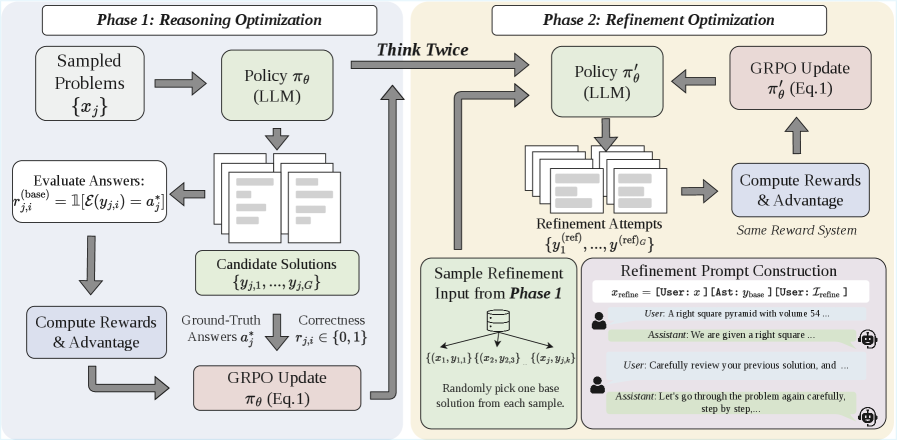
已有的补救办法大多需要额外资源:训练一个专门挑错的批评模型(critic)、为每一步推理单独打分的过程奖励,或者人工撰写的批评数据。ThinkTwice 走了另一条路:不引入任何新信号,让模型用同一个对错奖励,把“解题”和“修正自己”当成两个都需要练习的动作。
同一个奖励,用在两个动作上
训练步骤成对出现。第一步是常规的 GRPO(一种常用的 RLVR 算法:同一道题采样多个解,按组内相对优劣更新模型):模型对每道题给出若干个解,按最终答案是否正确获得二元正确性奖励——只分对错,不给部分分。
第二步把这些解原样交还给模型,要求它在此基础上修正,再用同一个奖励更新。奖励函数没有任何变化,变化的只是它被同时应用于“解题”和“改题”两种行为。整条训练流程不需要批评模型、不需要过程奖励、也不需要人工批评数据,开销只比常规方法多约 3%。
五个数学基准上的验证
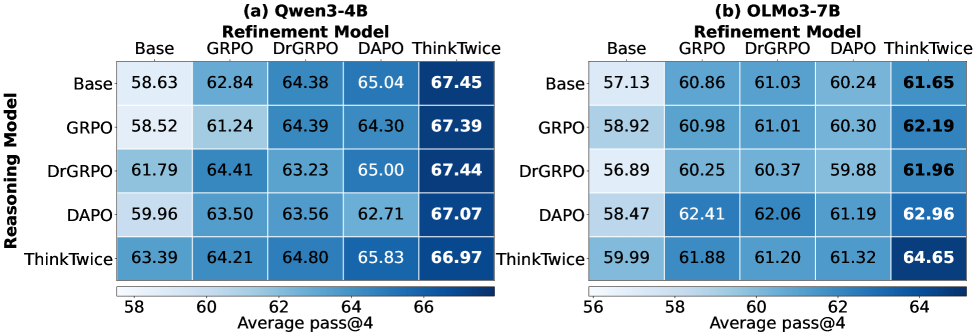
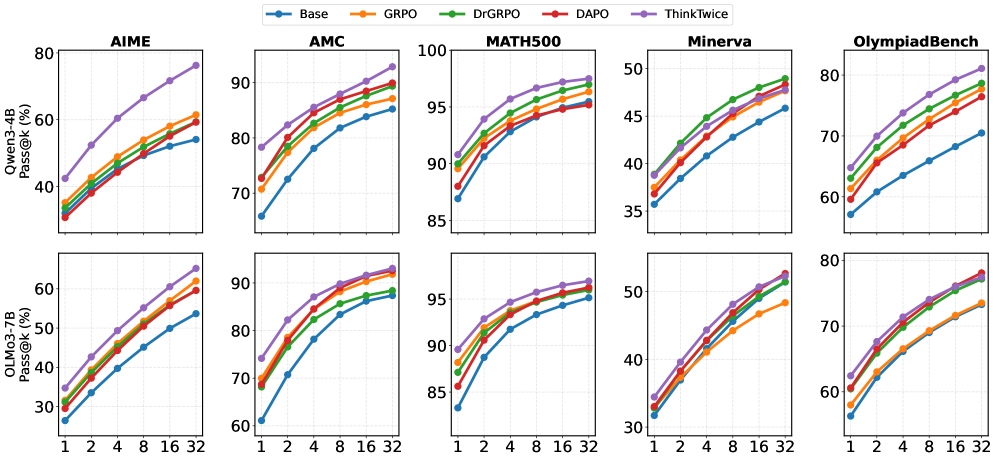
实验覆盖 MATH500、AIME 2024、AMC、Minerva Math、OlympiadBench 五个数学评测集,以及 Qwen3-4B 和 OLMo-3-7B 两个模型家族。代表性结果来自 Qwen3-4B 在 AIME 2024 上的 pass@4 成绩(允许作答 4 次,任一次正确即通过):
| 设置 | AIME pass@4 增益 |
|---|---|
| GRPO 单遍 | 基线 |
| ThinkTwice,不调用精修 | +5.0 |
| ThinkTwice,调用一次精修 | +11.5 |
两层提升的来源值得分开看:完全不调用精修时,ThinkTwice 训练出的模型一次作答已比基线高 5.0 个百分点——练习修正反过来改善了第一次解题;调用一次精修后,总提升达到 11.5 个百分点。
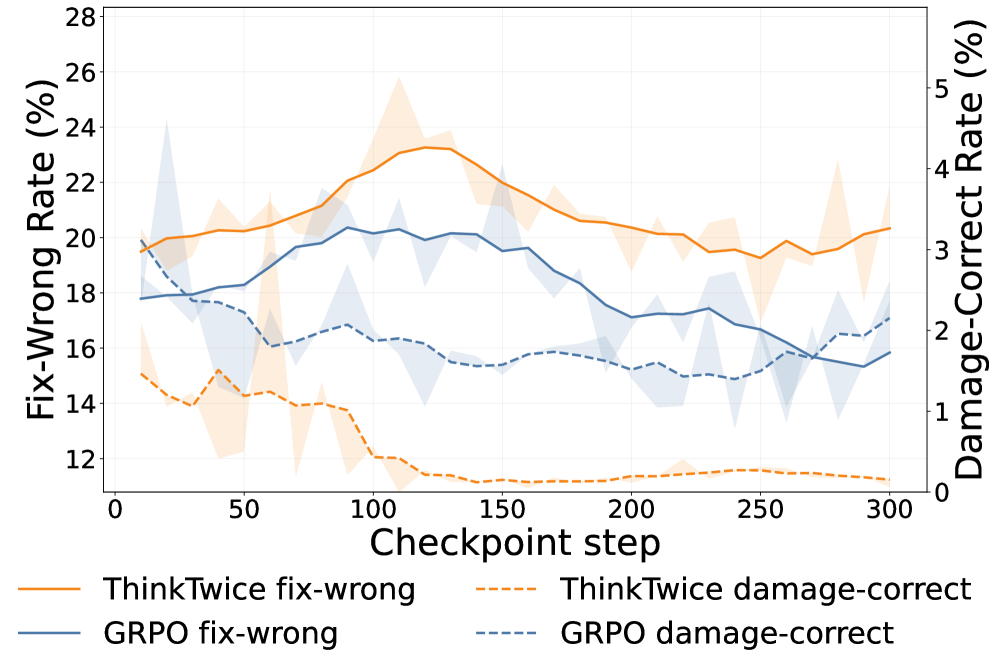
训练过程中还观察到一个有意思的现象:模型先学会“把错的改对”,随后逐渐学会“守住已经正确的答案”,形成一种没有人为设计的隐式课程。精修能力还能跨模型迁移——用它修正其他模型写出的解同样有效,说明它学到的并非只是自己的输出风格。