Can today's strongest coding agents actually ship a real mobile feature? We took 50 feature tickets straight out of Xiaohongshu's production iOS app — PRDs, Figma designs, ~500K lines of mixed Swift / Objective-C, and 449 human-written tests grading them — and pointed every leading agent × model combo at the work. The best score is 12%. The paper is now in KDD 2026's Applied Data Science Track at the main conference (CCF-A).
Why mobile is the honest hard test
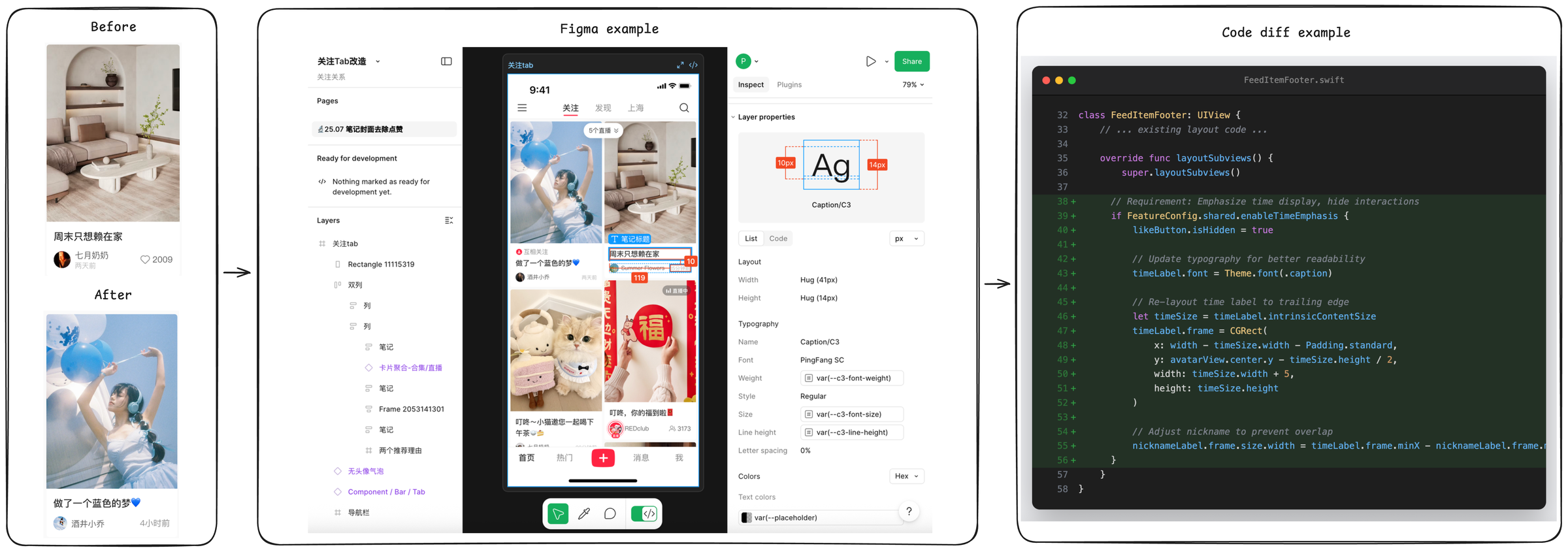
Most coding-agent benchmarks ask a model to fix a bug it can see, against a test that already exists, inside a repo that may well have been in pretraining. Real mobile work is none of that. Tasks come in as feature tickets, not bug reports. The spec lives in a PRD and a Figma file, not a GitHub issue. The fix usually touches UI, data, interaction, feature flags, and engineering conventions at the same time. And the codebase is hundreds of thousands of lines that the model has not seen.
SWE-Bench Mobile puts all of that in one evaluation. The question it answers: can a complete agent system take a real product requirement and land it cleanly inside a production iOS app?
What's actually in it
| Task source | Xiaohongshu's production iOS app |
| Task type | Feature additions, not bug fixes |
| Codebase size | ~500K lines of mixed Swift / Objective-C |
| Task inputs | PRD + Figma design + reference images + codebase snapshot |
| Evaluation scale | 50 tasks, 449 human-written tests |
| Release format | Hosted challenge with a public leaderboard |
| Venue | KDD 2026 Main Conference (CCF-A) |
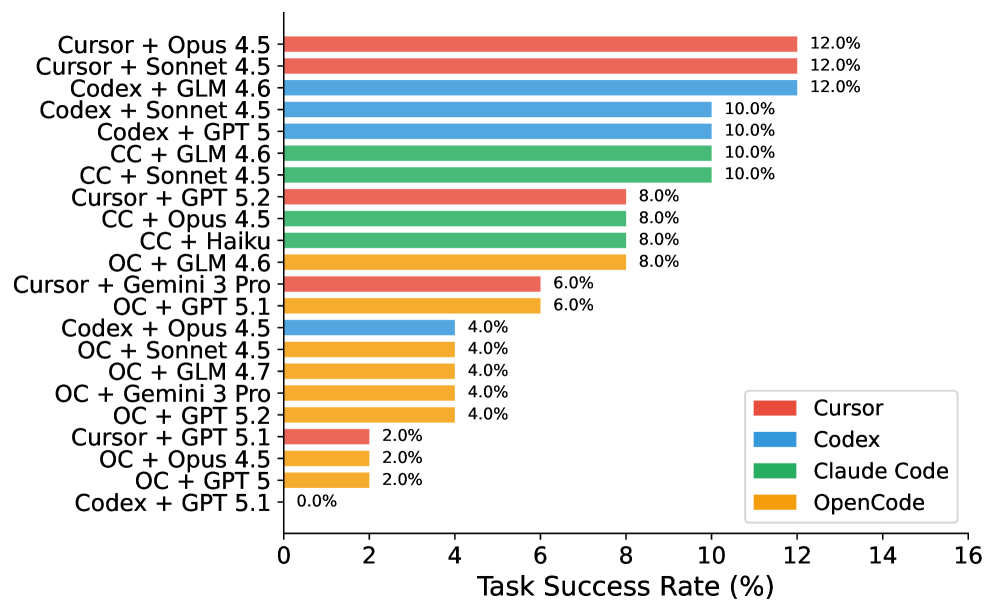
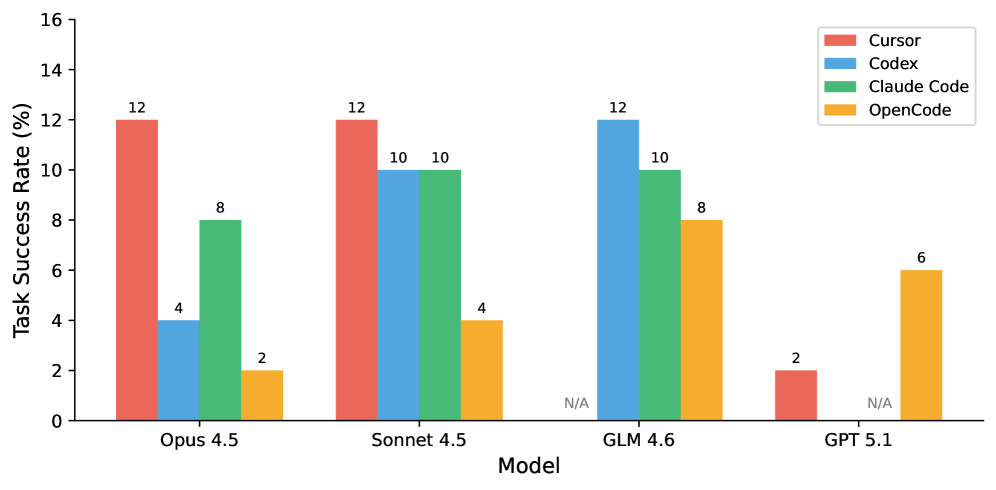
The leaderboard, in one chart
Five findings backed by the data
- Same model, different agent — up to 6× spread. It's the scaffold, not just the LLM. Reports that name only the model are missing half the story.
- Top score 12%. Top test pass rate 28.1%. Agents land partial wins, then trip over production details.
- Simpler beats fancier. A plain "Defensive Programming" prompt outperforms more elaborate strategies by +7.4 pp on test pass rate.
- Cross-module work remains the weakest link. Tasks touching 7+ files drop to 2% success. Localized changes are far easier.
- What breaks the patch isn't the code — it's the conventions. Missing feature flags, half-built data models, the one file no one remembered, UI components that don't match the rest of the app.
Submit your stack to the leaderboard
SWE-Bench Mobile is a hosted challenge for coding-agent teams, foundation-model vendors, and mobile-development researchers. Submissions run server-side, so the test set never leaks into anyone's training data. What it offers is an evaluation coordinate system that stays close to real shipping mobile engineering.
Submit your agent to the leaderboard
The hosted challenge takes submissions today; one submission places you alongside every other team. Project page and public leaderboard are live; the paper is on arXiv and now in the KDD 2026 Main Conference proceedings (CCF-A).