当前最强的 AI 编程智能体,真能独立做一款工业级移动应用吗?我们把小红书生产 iOS 应用里的 50 个真实功能任务原样搬上来——PRD、Figma 设计稿、约 50 万行 Swift / Objective-C 混合代码、449 条人工写的测试一并保留——让所有主流"智能体 × 模型"组合上去做。最高任务通过率:12%。论文已正式收录于 KDD 2026 应用数据科学方向(主会,CCF-A 顶会)。
为什么移动端才是真考题
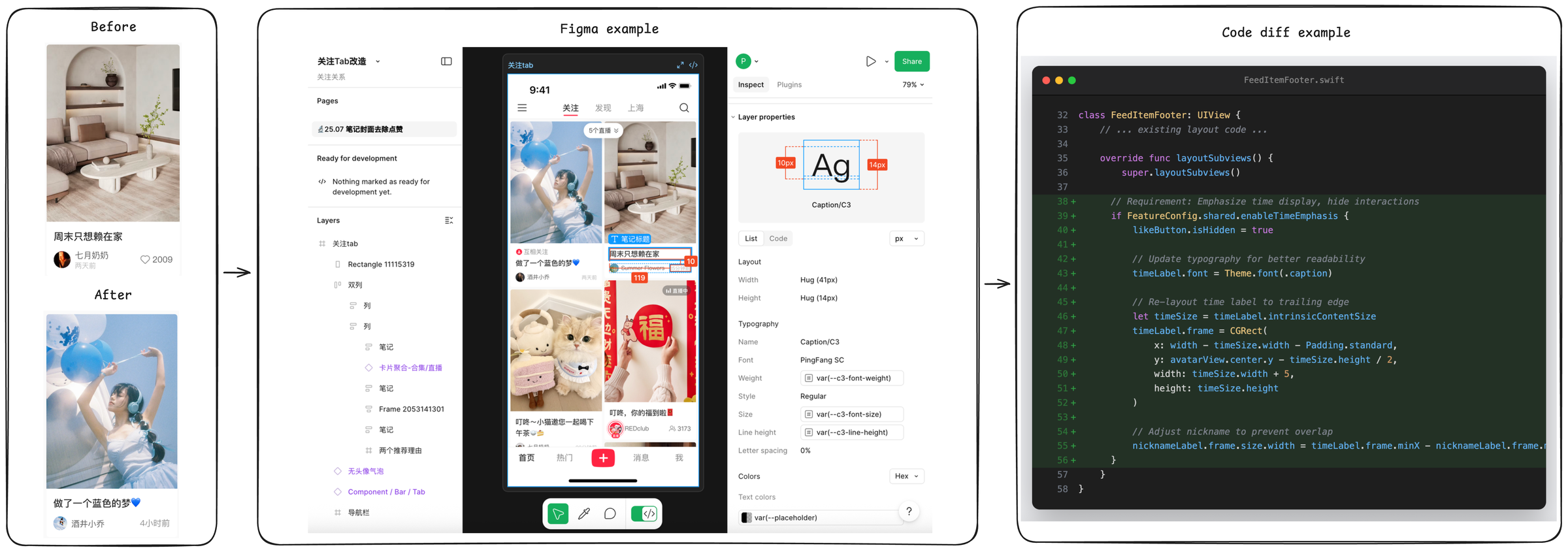
大多数代码智能体评测是这样的:让模型修一个看得见的 bug,对着一份已经写好的测试,在一个早就出现在预训练数据里的开源仓库上。真实移动端开发完全不是这回事。任务进来时是产品功能单,不是 bug 报告;规格放在 PRD 和 Figma 里,不在 GitHub issue 里;一次改动通常同时牵动 UI、数据、交互、feature flag 和工程规范;代码库是几十万行模型从没见过的真实工程。
SWE-Bench Mobile 把这些一起放进同一套评测里。它要回答的问题是:一整套智能体系统能不能把真实产品需求稳稳落到一款在线 iOS 应用里。
这套基准里到底有什么
| 任务来源 | 小红书在线生产 iOS 应用 |
| 任务类型 | 功能新增,不是单纯改 bug |
| 代码规模 | 约 50 万行 Swift / Objective-C 混合代码 |
| 任务输入 | PRD + Figma 设计 + 参考图 + 代码库快照 |
| 评测规模 | 50 个任务,449 条人工写的测试 |
| 开放方式 | 托管挑战,公共排行榜持续更新 |
| 收录会议 | KDD 2026 主会(CCF-A 顶会) |
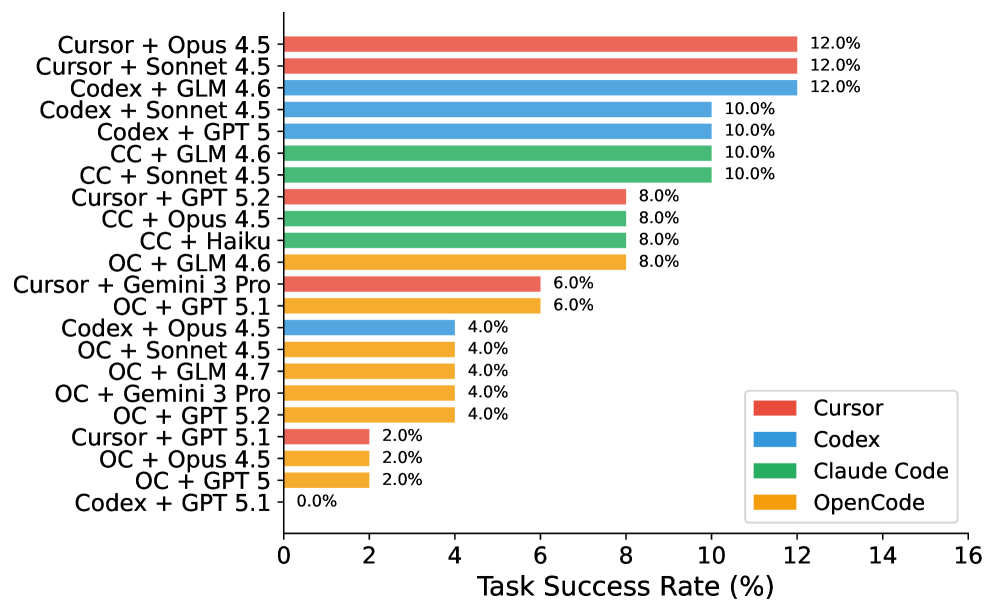
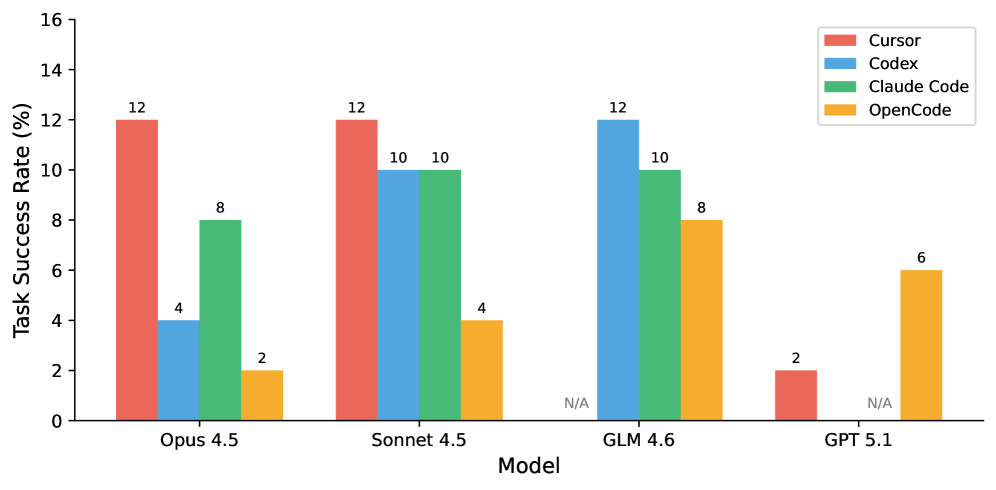
一张图看完整张榜
五个有数据支撑的发现
- 同一个模型,换个智能体能差出 6 倍。脚手架和模型一样关键;只报告模型名字的评测,丢掉了一半故事。
- 榜首任务通过率 12%,最高测试通过率 28.1%。智能体能完成一部分关键改动,但卡在生产细节上。
- 复杂提示不一定赢简单提示。一句"防御式编程"提示比花哨提示策略多通过 7.4 个百分点。
- 跨模块改动仍是最薄弱的环节。改动涉及 7 个以上文件时,成功率直接掉到 2%。小补丁明显容易得多。
- 卡住智能体的往往不是代码,是规范。feature flag 漏加、数据模型没补齐、关键文件没改到、UI 和现有产品对不上——一条都不能少。
把你的智能体提交上榜
SWE-Bench Mobile 以托管挑战形式开放,服务代码智能体团队、基础模型团队和移动开发研究者。提交在服务器端执行,测试集不会泄漏进任何人的训练数据。它要给出的,是一个贴近真实工程现场的评测坐标系。
想让你的智能体上榜?
托管挑战即刻开放提交,提交一次即可与所有团队横向比较。项目主页和公共排行榜已上线,论文已收录于 KDD 2026 主会(CCF-A),同步可在 arXiv 阅读。